
引言
在具身智能(Embodied AI)领域,构建高保真且具备物理交互能力的3D仿真环境是训练机器人策略的基石,而“桌面场景”作为机器人执行精细操作的核心舞台,其生成质量尤为重要。面对现有生成方法普遍存在物理冲突严重、难以直接用于交互仿真的痛点,地瓜机器人(D-Robotics)联合中国科学院大学、地平线、中科院自动化所创新性地提出了TabletopGen:一个无需训练、全自动的统一生成框架,能够通过逐个实例的3D重建和新颖的姿态-尺度对齐方法,从文本或单张图像直接生成多样化、实例级、可交互的3D桌面仿真场景。大量的实验与用户研究表明,TabletopGen在视觉保真度、布局准确性、物理合理性等方面显著超越当前最先进方法,生成的场景不仅支持灵活的模块化编辑,更能高度适配复杂的机器人操作任务仿真,填补了具身仿真中对高质量、可交互桌面环境的需求空白。

🔗 Project Page:
https://d-robotics-ai-lab.github.io/TabletopGen.project/
🚀 Code:
https://github.com/D-Robotics-AI-Lab/TabletopGen
诚邀扫码,添加微信入群获取
最新方法资讯,并与作者交流探讨

WeChat QR of Project Lead
TabletopGen:生成高质量、实例级、可交互的3D桌面场景
核心贡献
(1)统一、全自动化框架TabletopGen:一个无需训练、全自动的生成框架,能够通过逐实例的3D重建和两阶段的姿态-尺度对齐,从文本或单张图片生成多样化、实例级、物理可交互的3D桌面场景。
(2)新颖的3D姿态和尺度对齐方法:该方法能够从2D场景图像中,通过可微旋转优化器(DRO)精确恢复物体的旋转,利用俯视空间对齐(TSA)机制稳健地推断物体的平移和尺度,从而组装成物体位置精确、无碰撞的3D场景。
(3)卓越的性能:广泛的实验和大规模用户研究表明,TabletopGen在视觉质量、布局准确性和物理合理性方面显著超越了现有最先进的生成方法,能够生成现实感极强、碰撞率极低的桌面场景,并具有较高的泛化性。
背景介绍
3D 场景生成在具身 AI、VR/AR、游戏和数字孪生等领域具有广泛应用。 尤其是近年来,具身智能的快速发展要求3D场景不仅要具有照片级的真实感,更需要场景中的每个实例都能在物理层面上进行交互,以支持在仿真环境中训练机器人策略。
在当前的具身智能研究中,一个核心目标是使机器人能够执行复杂的物体操作,而桌面场景(Tabletops)是此类环境的“最后一步”,是大多数精细交互和复杂机器人操作任务的基础舞台。 因此,自动化、大规模地生成高保真、可交互的桌面场景,对于推进具身操作策略学习至关重要。
一个真正适用于模拟环境和机器人训练的桌面场景,必须满足以下三个核心标准:
-
可交互的高质量实例:场景中每个物体都是独立的、几何完整的3D模型,允许对单个实例进行精细操作;
-
符合功能语义的布局:物品的摆放应符合功能和常识(例如,笔记本在桌面中心且面朝用户,鼠标位于键盘旁边等),而非简单的堆叠放置;
-
精确且物理合理的位置关系: 每个实例的位置和姿态都必须准确,以确保场景无碰撞、无穿透或漂浮。
然而,现有的方法在满足这些高标准方面存在严重的不足,主要体现在以下几个方面:
(1)文本驱动方法的局限性: 这类方法,例如Holodeck[1],利用大语言模型(LLM)进行语义和空间推理来合成场景。它们利用大语言模型(LLM)直接生成 3D 布局,或者通过生成场景图或空间约束,再进行布局可行性的优化。然而,这两类路径通常都依赖于从固定的 3D 资产库中检索模型,这极大地限制了场景的风格一致性和几何灵活性。更关键的是,这些方法大多专注于大规模的室内场景生成,难以捕捉桌面场景特有的高密度、强功能性的细粒度布局特征。
(2)单图像重建方法的瓶颈: 单图像重建需要解决图像对齐、单视角遮挡和复杂的空间关系等难题。ACDC[2]这类检索式方法虽然可以将实例与 3D 库匹配,但受限于资产库的多样性不足和几何形状的差异,难以生成和原图相似的3D场景。MIDI[3]这类基于扩散的方法能一次性合成与输入视图一致的场景,但往往面临多视角不一致以及被遮挡物体几何缺失的问题。而组合式的生成式方法,例如Gen3DSR[4],则通过分别重建并对齐每个实例提高了灵活性,但在单视角的严格约束下,它们仍难以可靠地恢复被遮挡或隐藏部分的精确位姿,导致重建结果频繁出现物体穿透、悬浮等物理不合理的布局。
(3)专用桌面场景数据的稀缺: 相比于丰富的房间级数据集,专用的桌面场景资源极其稀缺。现有的工作中,TO-Scene[5]虽然提供了大规模的3D桌面场景数据,但其主要依赖人工构建,缺乏自动化生成能力。近期的 MesaTask[6]虽然引入了“任务到场景”的生成方案,但其仅关注在固定桌面上放置物体,并未对完整的桌子几何进行建模,且依然依赖于资产检索,无法满足资产多样性和精细程度的需求。
面对上述挑战,地瓜机器人提出了TabletopGen:一个统一的、无需训练的生成框架。与现有方法不同,TabletopGen不依赖有限的资产库,而是能够从文本描述或单张图像输入出发,对每个物体都进行单独的生成,从而得到风格一致、几何完整且布局合理的实例级、交互式 3D 桌面场景,填补了具身仿真中对高保真桌面环境的需求空白。
方法概要
TabletopGen介绍

生成高保真、可进行物理交互的3D模拟桌面场景对于具身人工智能至关重要,尤其是在机器人操作策略学习和数据合成方面。然而,当前由文本或图像驱动的3D场景生成方法主要聚焦于大规模场景,难以捕捉桌面场景所特有的高密度布局和复杂空间关系。
为解决这些挑战,地瓜机器人提出了TabletopGen——一个无需训练、全自动的框架,用于生成多样化、实例级的交互式3D桌面场景。TabletopGen接受参考图像作为输入,该参考图像可由文本到图像模型合成,以增强场景的多样性。随后,对参考图像进行实例分割和补全,得到每个实例的图像。每个实例会被重建为3D模型,之后进行规范坐标对齐。对齐后的3D模型会经过姿态和尺度估计,再被组装成无碰撞、可用于模拟的桌面场景。
TabletopGen框架的一个关键组件是一种新颖的姿态和尺度对齐方法,它将复杂的空间推理分解为两个阶段:用于精确旋转恢复的可微分旋转优化器,以及用于稳健平移和尺度估计的顶视空间对齐机制,从而能够从2D参考中实现精确的3D重建。
大量实验和用户研究表明,TabletopGen实现了最先进的性能,在视觉保真度、布局准确性和物理合理性方面显著超越现有方法,能够生成具有丰富风格和空间多样性的逼真桌面场景。TabletopGen的代码将公开可用。
框架流程
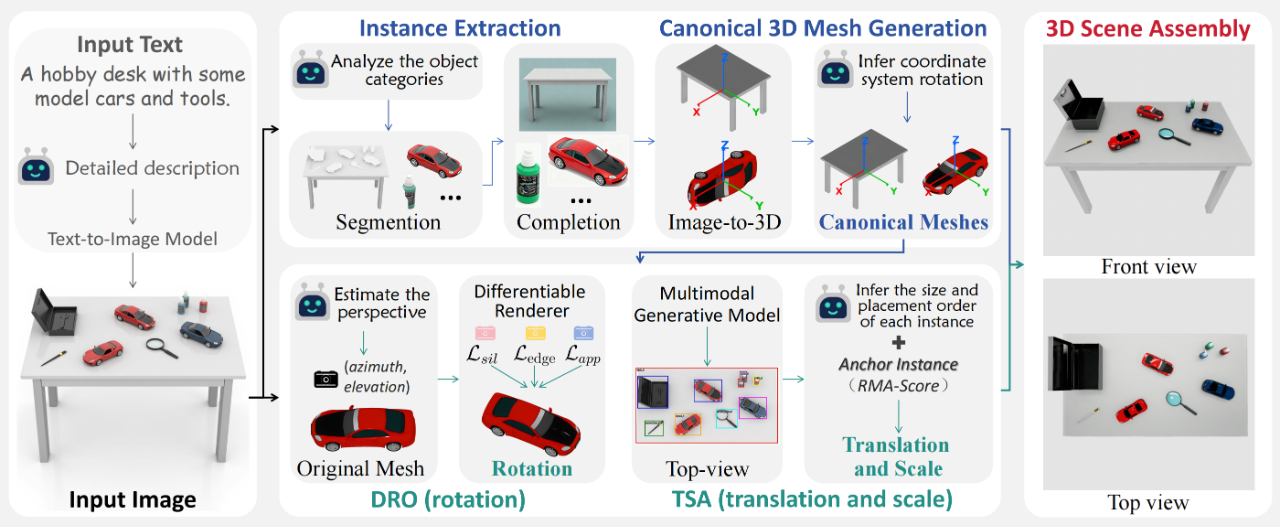
TabletopGen既接受文本(文本会先被转换为参考图像)输入,也接受单张图像输入。从图像出发,TabletopGen按四个阶段进行处理:
(1)实例提取阶段会进行物体类别分析、图像分割和2D补全操作,以获取完整、高分辨率的单实例图像。
(2)规范3D模型生成阶段利用Image-to-3D模型生成实例的mesh,并通过基于多模态大语言模型(MLLM)的对齐方法,将每个实例的3D模型都规范到标准桌面坐标系。
(3)核心的姿态与尺度对齐阶段用于恢复空间布局。其中,可微分旋转优化器(DRO)通过优化一个三模态损失来估计最匹配的旋转角度,而俯视空间对齐(TSA)机制会合成场景的俯视图像,并结合MLLM的推理能力,通过RMA分数选择一个锚点实例,进而推断每个实例的平移量和尺度。
(4)3D场景组装阶段在仿真器(NVIDIA Isaac Sim)中整合所有实例模型及其姿态和尺度,生成最终的无碰撞、可交互的3D桌面场景。
实验验证
定量对比
评价指标选择如下:
-
视觉与感知质量(Visual & Perceptual):采用LPIPS、DINOv2和CLIP三个指标来衡量生成场景与参考图像之间的感知相似度、视觉一致性和语义对齐度。
-
多维度 GPT 评估(GPT Evaluation): 使用GPT-4o在 1-7 分的量表上评估场景的视觉保真度(VF)、图像对齐度(IA)和物理合理性(PP),并给出不同方法的总体排名(OR)。
-
碰撞比例(Collision Rate):计算生成场景的碰撞物体对比例(Col_C),以及包含碰撞的场景占总场景的百分比(Col_S),以此衡量生成场景的物理合理性。
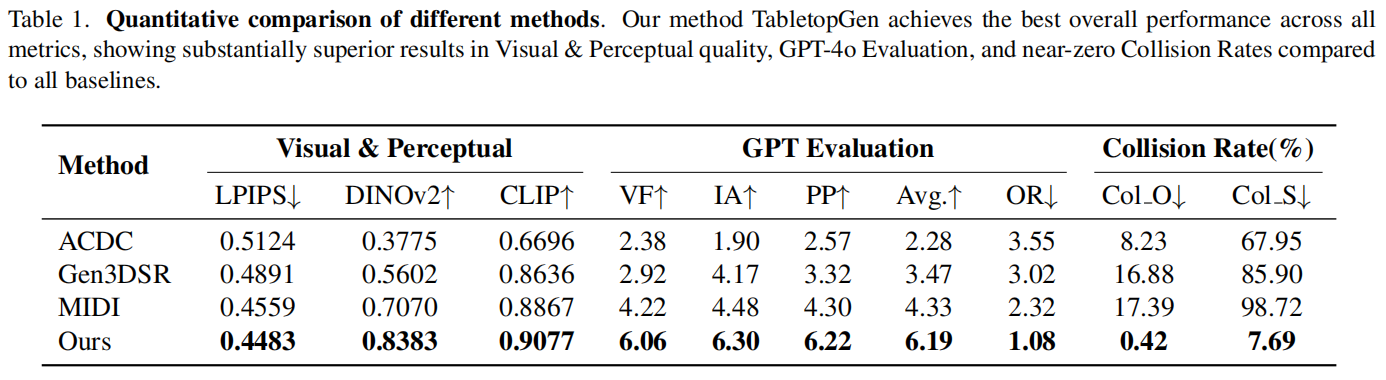
TabletopGen在三个评估方面的所有指标上均取得了最佳性能,明显优于所有基线方法。
-
在视觉与感知质量方面,TabletopGen的LPIPS、DINOv2和CLIP评分均为最优。这得益于“先实例,后对齐”的设计理念,该理念首先确保每个实例的高保真重建,随后实现精确的姿态和尺度对齐。
-
在多维度 GPT 评估中,TabletopGen获得了最高的平均分(6.19)——比次优的MIDI高出43%,并在总体排名(OR)中位居榜首。这表明结果在真实感和语义合理性方面更具优势。
-
碰撞比例,即物理合理性的差距最为显著。现有的3D场景生成方法难以处理具有复杂空间关系的高密度桌面布局,它们的Col_O通常在8%–17%左右,场景级的Col_S更是高达67%–98%。相比之下,TabletopGen的Col_O接近零(0.42%),Col_S也仅为7.69%。这一压倒性优势证明了TabletopGen在生成无碰撞、可交互桌面场景方面的稳健性和实用价值。
用户研究
我们进一步开展了一项全面的用户研究,以评估场景质量和用户偏好,共有128名用户参与其中。每位参与者被随机分配8个场景;为确保公平性,不同方法的结果展示顺序被完全随机化。参与者采用7分制,从三个标准,即视觉保真度(VF)、图像对齐度(IA)和物理合理性(PP)方面,对生成的场景进行评分,并根据总体偏好OP选择最喜欢的场景。
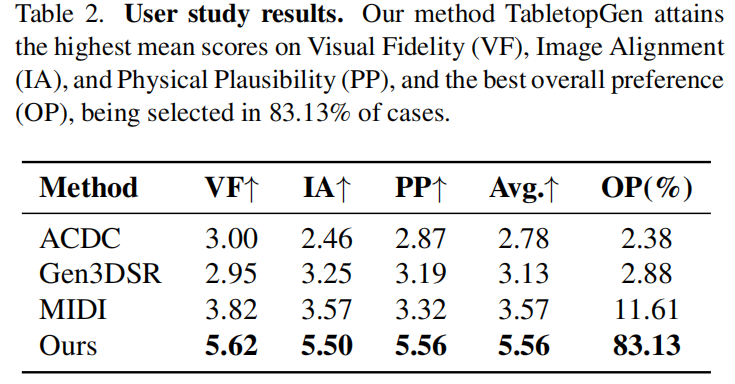
TabletopGen在每一项标准上都显著优于所有基线方法。TabletopGen的平均得分为5.56,远高于排名第二的方法(3.57)。
当被问及总体偏好(OP)时,TabletopGen的结果在83.13%的情况下被选中,这证实了其生成的场景看起来更真实,对用户而言更具说服力。
定性对比

与单图像重建的方法相比,TabletopGen生成了一致的物体数量和类别、具有统一风格的精细模型、语义连贯的布局以及无碰撞的物体摆放。
相比之下,基于检索的方法(例如ACDC)受限于其固定的资产库,无法匹配特定的物体风格和形状。生成式重建方法(例如Gen3DSR和MIDI)在处理遮挡方面存在困难,导致实例生成不完整、物体相互穿透以及布局不准确。

我们还将TabletopGen与最新的文本驱动的桌面生成方法MesaTask[6]进行了比较,以展示了“文本到场景”生成能力。MesaTask会检索资产并将其放置在固定平面上,这限制了多样性和保真度,偶尔还会导致轻微的碰撞(例如图中场景2的遥控器和罐子)。相比之下,TabletopGen会生成整个场景,包括风格一致的桌子,从而呈现出更逼真的视觉效果、更丰富的实例数量、更合理的布局以及无碰撞的排列。
消融实验
TabletopGen的布局估计能力来自于其核心的DRO和TSA模块,分别用来估计实例的旋转以及平移与尺度。我们通过将任一模块替换为一个简单的仅基于多模态大语言模型的基线来进行消融实验,以验证各模块的功能与重要性。替换的方式为:当移除一个模块时,通过直接提示 ChatGPT 从参考图像中估计对应的参数(旋转/平移/尺度)来替代其该模块的功能。
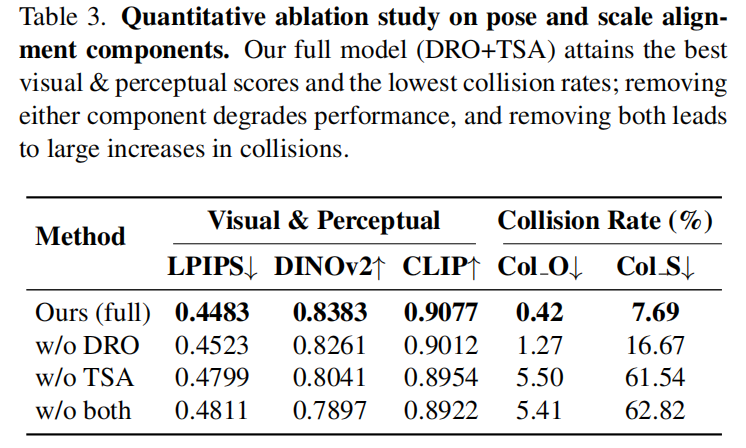
移除任何一个模块(w/o DRO、w/o TSA)都会降低视觉与感知分数,并显著增加碰撞的比例。而同时移除两个模块(w/o both)则会大幅度地降低生成场景的质量,尤其是场景碰撞率(Col_S),导致其难以直接用于具身仿真。
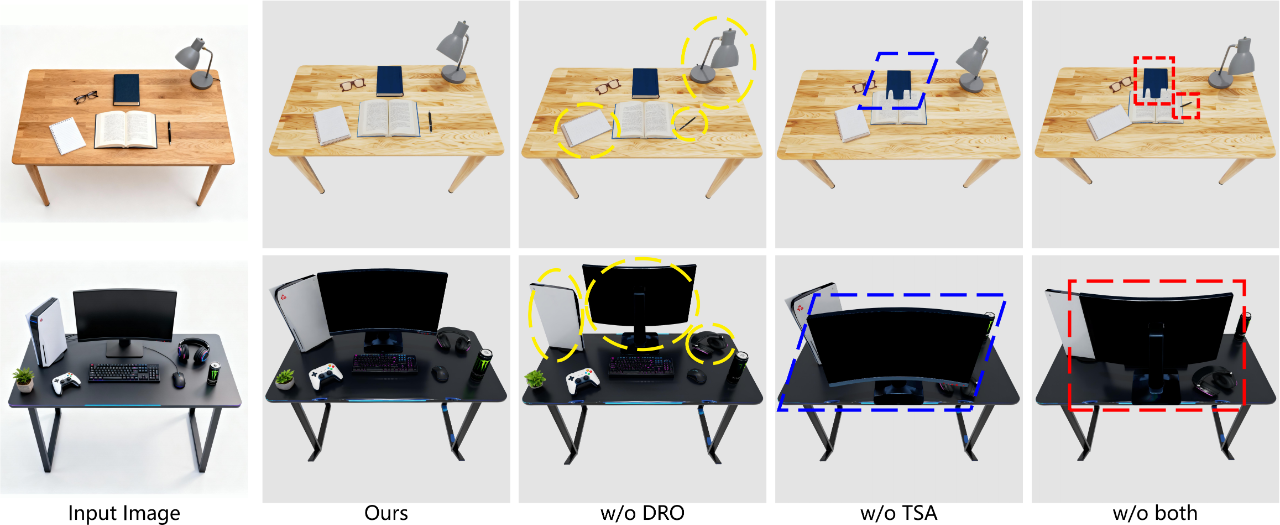
w/o DRO 的基线无法恢复正确的旋转,而w/o TSA 的基线会产生不合理的放置和尺度漂移。w/o both 的情况则会加剧这些错误,导致最终场景出现严重的碰撞(例如,书籍相互穿透)和遮挡(例如,显示器前移并挡住其他物体)。
相比之下,完整模型(Ours)的结果与输入图像高度匹配,并呈现出无碰撞的布局。
扩展应用
(1)真实图像的重建(Real-to-Sim):我们在现实中实拍的照片上将TabletopGen与MIDI(上述对比实验中第二好的方法)进行了比较,以验证TabletopGen的Real-to-Sim能力。

相比之下,TabletopGen 能保留实例数量和风格,恢复准确的布局,并生成无碰撞、可用于模拟的场景。这种Real-to-Sim的路径有助于弥合具身操作中Sim与Real的差距。
(2)场景编辑能力:得益于TabletopGen框架的逐实例生成和对齐方式,TabletopGen支持模块化编辑,即可以任意替换对象而无需重新处理整个场景。
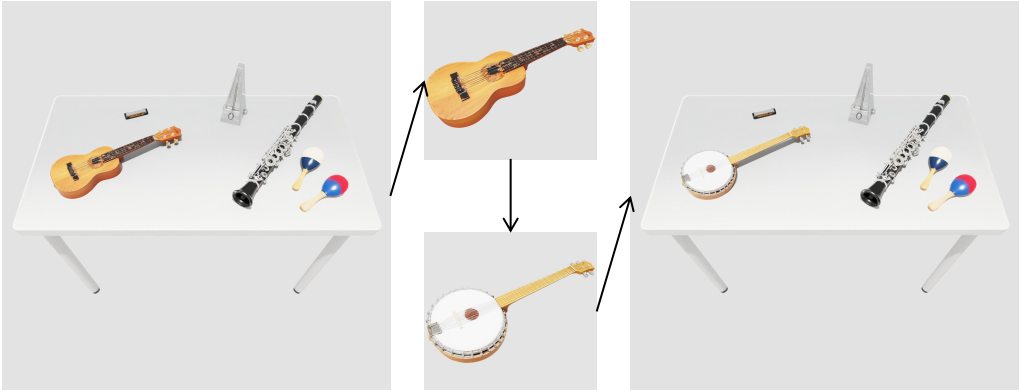
我们生成“班卓琴”的模型,并利用估计的“尤克里里”的位姿将其插入,从而用班卓琴替换了尤克里里,而全局布局仍能保持不变。
(3)机器人操作仿真:我们利用NVIDIA Isaac Sim仿真器,将生成的桌面放置到室内场景中,并导入带有平行夹爪的 Franka Emika Panda 7 自由度机械臂来执行一系列复杂的抓取和放置动作,以展示TabletopGen生成的场景在物理层面的可行性以及在具身操作任务中的适用性。
机械臂在两种常见的桌面环境(厨房桌和咖啡桌)中成功执行了序列的抓取-放置任务,期间没有出现模型穿透或不稳定接触等情况。这表明TabletopGen生成的桌面场景可直接用于交互,其物体模型和碰撞属性能够完美适配具身仿真环境和机器人操作策略的学习。
未来工作
地瓜机器人在场景生成的长期愿景是通过高保真、可交互的场景生成技术,构建通用的具身智能仿真系统,从而实现Real-Sim-Real的闭环,有效弥合仿真与现实之间的差距,推动具身操作策略在真实世界中的高效泛化。TabletopGen是我们在这条技术路线上迈出的坚实第一步。我们的后续规划是:
(1)从“桌面”走向“全场景”:未来的工作将尝试打破单一场景的限制,把当前框架推广到构建能够覆盖家庭、工业、办公等多种现实环境的复杂3D场景,为机器人更丰富的交互舞台。
(2)构建具身数据引擎:场景生成的最终价值在于数据。我们将利用生成的无限且多样化的 3D 场景,搭建高效的具身数据引擎,将大规模高质量的仿真场景服务于机器人策略的训练与学习,加速实现Sim-to-Real的策略迁移与部署。
参考文献
[1] Holodeck: Language guided generation of 3d embodied ai environments.
[2] Automated creation of digital cousins for robust policy learning.
[3] Midi: Multi-instance diffusion for single image to 3d scene generation.
[4] Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view.
[5] To-scene: A large-scale dataset for understanding 3d tabletop scenes.
[6] Mesatask: Towards task-driven tabletop scene generation via 3d spatial reasoning.





2025年,人形机器人产业迎来爆发拐点。特斯拉Optimus量产在即,华为、宇树等企业加速技术突破,行业正从“实验室研发”向“规模化落地”跃迁为打通产业链上下游协作壁垒,艾邦机器人正式组建"人形机器人全产业链交流群",覆盖金属材料、复合材料、传感器、电机、减速器等全硬件环节,助力企业精准对接资源、共享前沿技术!
扫码关注公众号,底部菜单申请进群
