

近日,大晓机器人联合上海交通大学、南洋理工大学、香港中文大学、香港大学等研究机构共同推出以空间智能为底层框架、跨不同具身本体的通用基础模型“ACE-Brain-0”,正式面向全行业开源。
ACE-Brain-0首次打破汽车、机器人、无人机等不同本体壁垒,贯穿空间认知、自动驾驶、低空感知、机器人交互,重新定义了物理世界智能的技术底层逻辑。其性能表现在涵盖空间认知、自动驾驶、低空感知、具身交互的24 个核心 benchmark 中,19 个取得当前模型中的 SOTA(排名第一) 成绩,全面大幅领先市场主流具身模型。ACE-Brain-0主要对标GPT-4o、Gemini 2.5-Pro、Qwen2.5-VL-7B-Inst、RoboBrain2.0-7B、MiMo-Embodied-7B等16个知名模型,将19个Benchmark具身模型最强基线准确率相对提升5%-97.8%。在衡量三维认知的MindCube,以82.1%的成绩,较最好的开源模型(InternVL3-8B)提升了97.8%。
目前,上述模型已应用于大晓机器人具身超级大脑模组A1,使搭载具身超级大脑A1的机器狗具备行业首创的端到端自主导航能力,并且基于VLA架构实现云端智能交互,让机器狗具备理解抽象指令、感知复杂环境、完成复杂任务的端到端闭环能力。
在城市人行道等复杂公共场景中,搭载ACE-Brain 的机器狗展现出卓越的导航与VLA能力。以图片场景为例,面对“估算行人和摩托车间距、判断是否有足够空间导航通过”的需求,ACE-Brain赋能机器狗精准完成三大核心动作:
依托空间认知能力,可精准量化行人和摩托车间距约0.5米,为导航决策提供可靠依据;通过视觉语言理解,清晰解析自然语言指令,实现“看—懂—判”的连贯交互,无需额外定制化指令;在导航决策中,既能判断空间足够通过,又主动提出“谨慎前行”的安全建议,兼顾效率与公共安全,适配复杂公共场景的移动需求。

搭载ACE-Brain 的机器狗,可精准识别前方车辆等障碍物,通过空间智能感知道路环境与目标位置,预判通行风险,主动判断 “应停下并安全绕行”,实现空间识别与目标预测的高效协同,保障复杂路况下的移动安全。

这种能力让机器狗在拥挤人行道、复杂路况等场景中,运用强大的空间智能技术底座,通过3D 场景建模、几何关系推理、空间定位等核心能力,既能精准感知环境,又能通过自然语言交互理解任务,实现安全、高效的自主导航,为公共巡检、应急响应等场景提供可靠支撑。
▎空间智能成为跨本体的“通用语言”
为了实现多任务,传统的办法是把所有任务数据混在一起,然后训练模型,盼望模型能够自己悟出来;但是ACE-Brain的思路则更像教育学:先让它建立“空间感”,学会理解世界中的前后左右、远近高低、视角变化和位置等空间几何关系,然后再去学不同任务中的具体技能。简单来说,就是先学会“怎么看懂世界”,再学会“怎么完成相关的任务动作”。
大晓机器人团队突破性发现,无论自动驾驶车辆、低空无人机还是机器人,尽管形态差异巨大,但都依赖三大核心空间能力:三维空间结构建模、几何关系推理、场景演化预测。
基于上述共性,大晓机器人首次提出以空间智能作为跨具身形态的“通用语言”,成为用以连接不同物理域的统一认知支架,为通用具身智能找到统一底座。
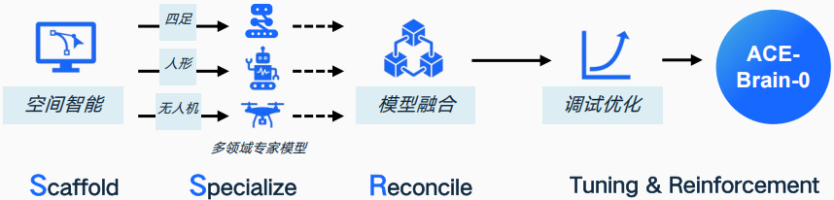
ACE-Brain-0架构
为打造统一的空间智能认知支架,ACE-Brain-0以空间信息为多模态自回归架构,实现了从单视角图像到多视角视频序列的认知统一处理。
在输入层,兼容单图、多图、视频等多模态视觉数据,搭配自然语言指令作为任务条件,覆盖所有具身场景的输入需求;
在表征层,通过通用视觉编码器提取领域无关的空间特征,经MLP 投影器映射为语言模型可理解的视觉令牌,并按 “通用、空间、驾驶、航空、具身” 分类组织,确保空间信息的结构化表达;
在推理层,由统一的LLM解码器实现跨模态融合推理,将空间认知转化为可迁移的统一表示,使不同具身场景的知识能基于空间逻辑自由流动。
这一设计的核心优势在于,无需为特定场景定制专用模块,仅通过空间智能的“通用表征”,就实现了跨域知识的自然迁移,彻底改变了“一个场景一套模型”的传统具身研发模式。
▎打造全新范式,解决跨本体训练困境
传统跨域训练面临两大困境,一是联合训练易引发梯度干扰,导致各领域能力“稀释”;二是序贯训练则会出现灾难性遗忘,学了新技能丢了旧能力。大晓机器人首创Scaffold-Specialize-Reconcile(SSR)三阶段训练范式,通过“先建共识、再练专长、后融知识”的路径,完美解决了这一矛盾。
首先,Scaffold(框架构建)筑牢通用空间基础。ACE-Brain-0利用大规模空间智能数据集训练空间专家模型,建立域无关的三维认知先验。这一步就像为所有具身能力打造“通用地基”,让后续领域训练都能基于统一的空间认知框架展开,避免了各领域“从零开始学空间”的重复劳动。
第二步,Specialize(域专精学习)实现隔离优化和强化专长。在空间框架上,ACE-Brain-0分别独立训练自动驾驶专家、机器人专家等领域模型。每个领域专家模型仅在自身专属数据集上微调,避免不同本体数据带来的梯度冲突,确保每个领域都能获得充分的专业化能力。
最后一步,Reconcile(跨域知识调和)实现数据无关的参数级融合。ACE-Brain-0通过任务向量空间对齐技术,在无需原始训练数据的条件下,将各领域专家的参数进行整合,从而同时联合训练中的优化干扰和顺序训练导致的灾难性遗忘。
▎四大能力首次统一,打造“一脑多形”样本
ACE-Brain-0首次在单一模型框架中实现四大核心具身能力的统一:空间认知、自动驾驶、低空感知、机器人交互。这一突破并非简单的能力“拼接”,而是基于空间智能的深度融合,其技术关键在于“共享认知结构”的构建。
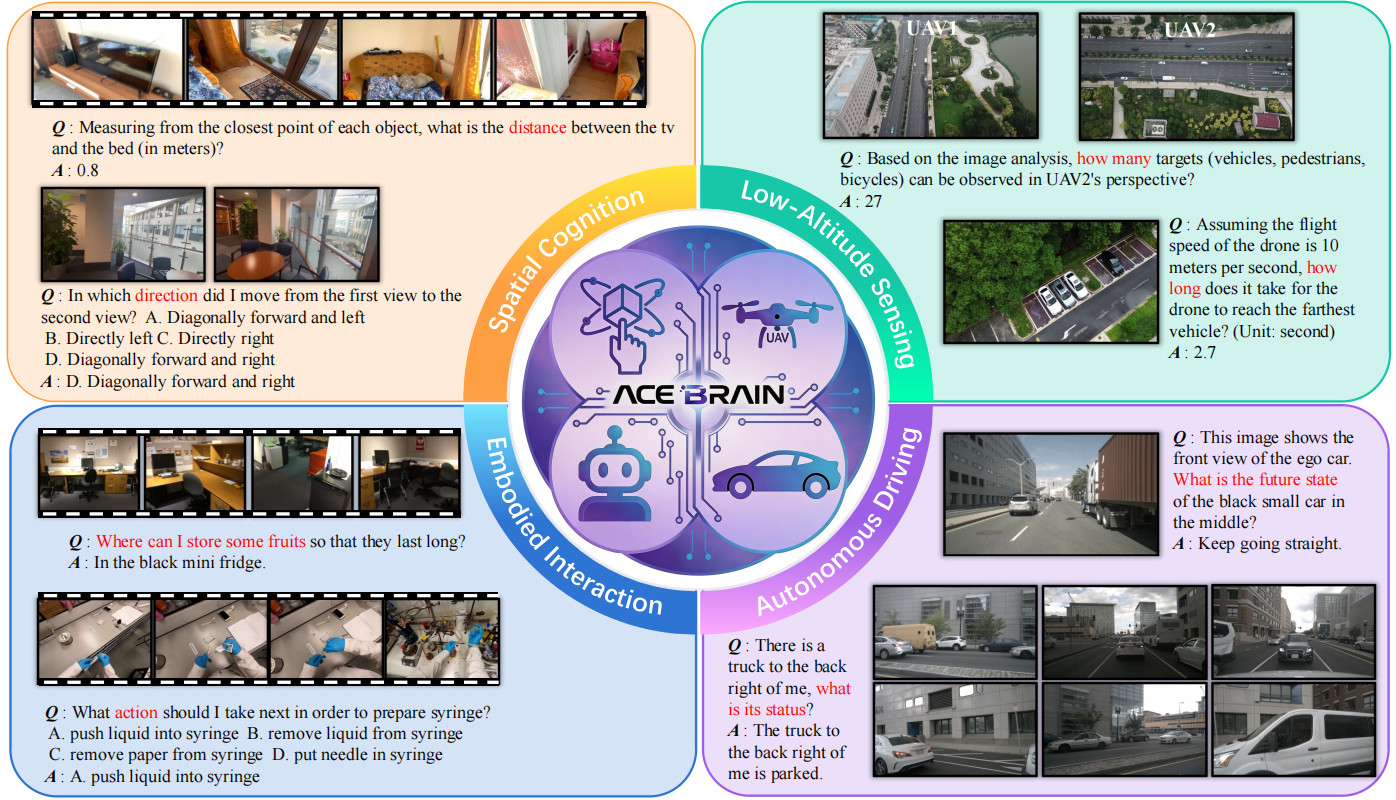
通过空间中心化建模,ACE-Brain-0让不同具身场景的认知逻辑实现统一。自动驾驶中的“车距判断”与机器人交互中的“抓取距离估算”,共享同一套空间距离推理机制;交通场景的“多视图融合”与机器人的“多视角物体识别”,依托相同的跨视角空间对齐技术。
这种“共享认知结构” 使得模型能在不同观察视角、运动尺度与任务语义之间自由切换,实现跨域理解与推理能力的自然迁移。
▎刷新19个榜单具身模型SOTA
ACE-Brain-0在涵盖空间认知、自动驾驶、低空感知、具身交互的 24 个核心 benchmark 中,对标GPT-4o、Gemini 2.5-Pro、Qwen2.5-VL-7B-Inst、RoboBrain2.0-7B、MiMo-Embodied-7B等16个知名模型,取得了19 个当前具身模型中的SOTA(排名第一) 成绩,同时将19个Benchmark具身模型最强基线准确率相对提升5%-97.8%,全面超越市场主流具身模型(如天工、北京智源、小米等)。
空间认知领域:
ACE-Brain-0参与了7项空间认知领域的权威基准评测,在具身智能模型阵营中斩获5项 SOTA, VSI(视觉空间智能)、MMSI(多模态空间智能)、SITE(空间语言理解)、SAT(空间视角变换)、Mindcube(受限视角三维建模)代表了不同维度的核心空间能力。
其中VSI(视觉空间智能)综合评估模型对空间布局、物体关系和尺度的理解与推理能力,ACE-Brain-0以63.3%的成绩领跑具身模型,验证了其空间认知的通用性;SAT(空间视角变换)考察从不同视角重构空间布局的能力,ACE-Brain-0以92.0% 的成绩,相较当前最好具身模型提升了16.9%,证明其在视角变换下的空间建模能力。
Mindcube(受限视角三维建模)评估有限视角下构建三维心理空间的能力,ACE 82.1%的表现碾压其他具身模型,较闭源模型 Gemini-2.5-Pro相对提升了42.5%,较最好的开源模型(InternVL3-8B)相对提升了97.8%,突破了遮挡和视角限制。
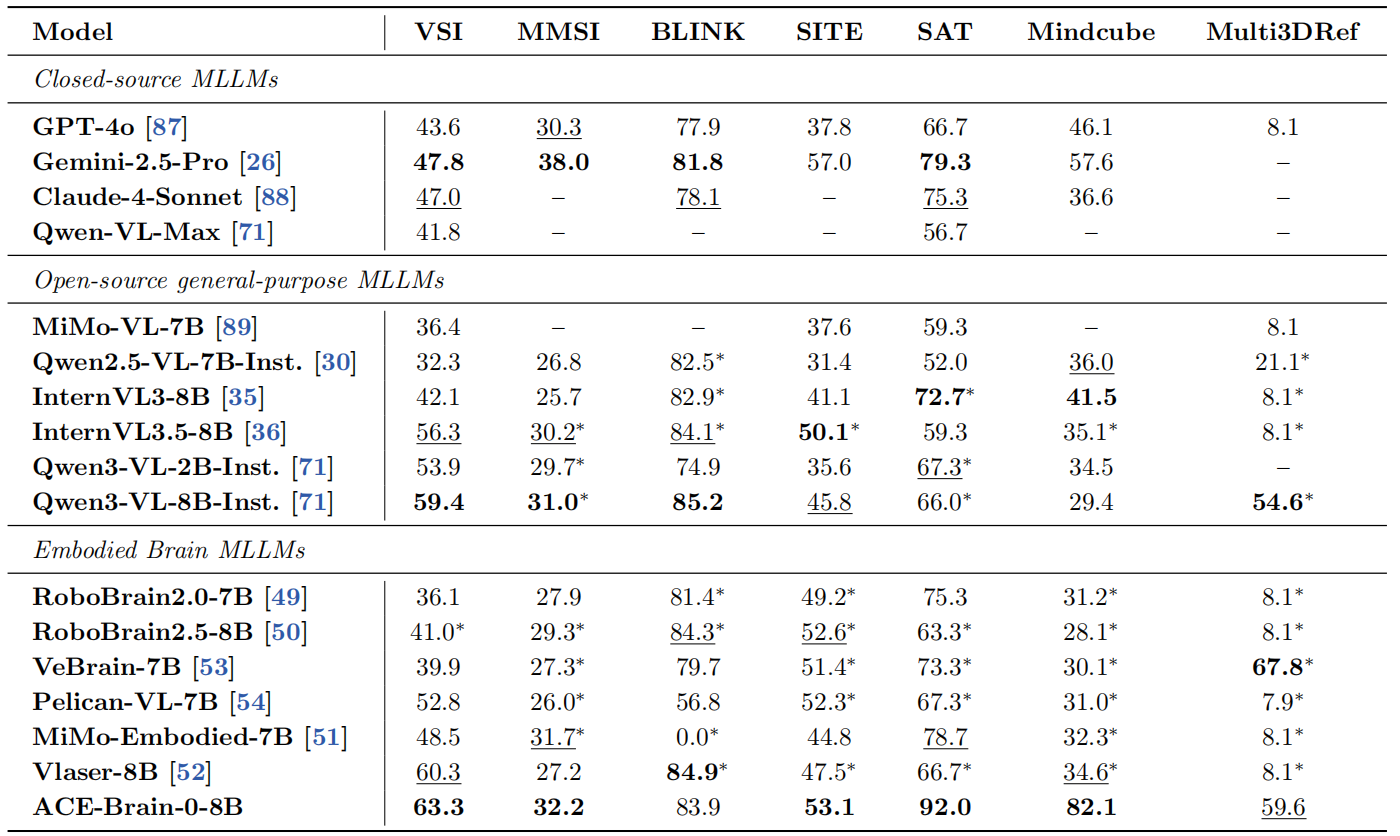
*代表基于上述模型复现/下划线代表次优表现/黑体代表最优表现
自动驾驶领域:
ACE-Brain-0在5个自动驾驶benchmark 上均取得领先表现,分别是MME-RealWorld(真实驾驶场景理解)、MAPLM(地图与道路结构理解)、DriveAction(驾驶行为理解)、NuscenesQA(多视图动态场景理解)、NuPlanQA(规划与交通规则理解),尤其在真实驾驶场景理解(MME-RealWorld)和规划推理能力(NuPlanQA) 等关键能力上实现显著提升。
其中MME-RealWorld(真实驾驶场景理解)主要评估模型在真实交通环境中的 多模态驾驶场景理解能力。ACE-Brain-0以71.2%的成绩,相比当前最强具身大脑模型相对提升18%。
NuPlanQA(规划与交通规则理解)重点考察模型在自动驾驶规划任务中的 交通信号理解与车辆状态推理能力。ACE-Brain-0取得91.7%的成绩,决策正确率超越所有具身模型基线,较Pelican-VL-7B模型相对提升近10%。
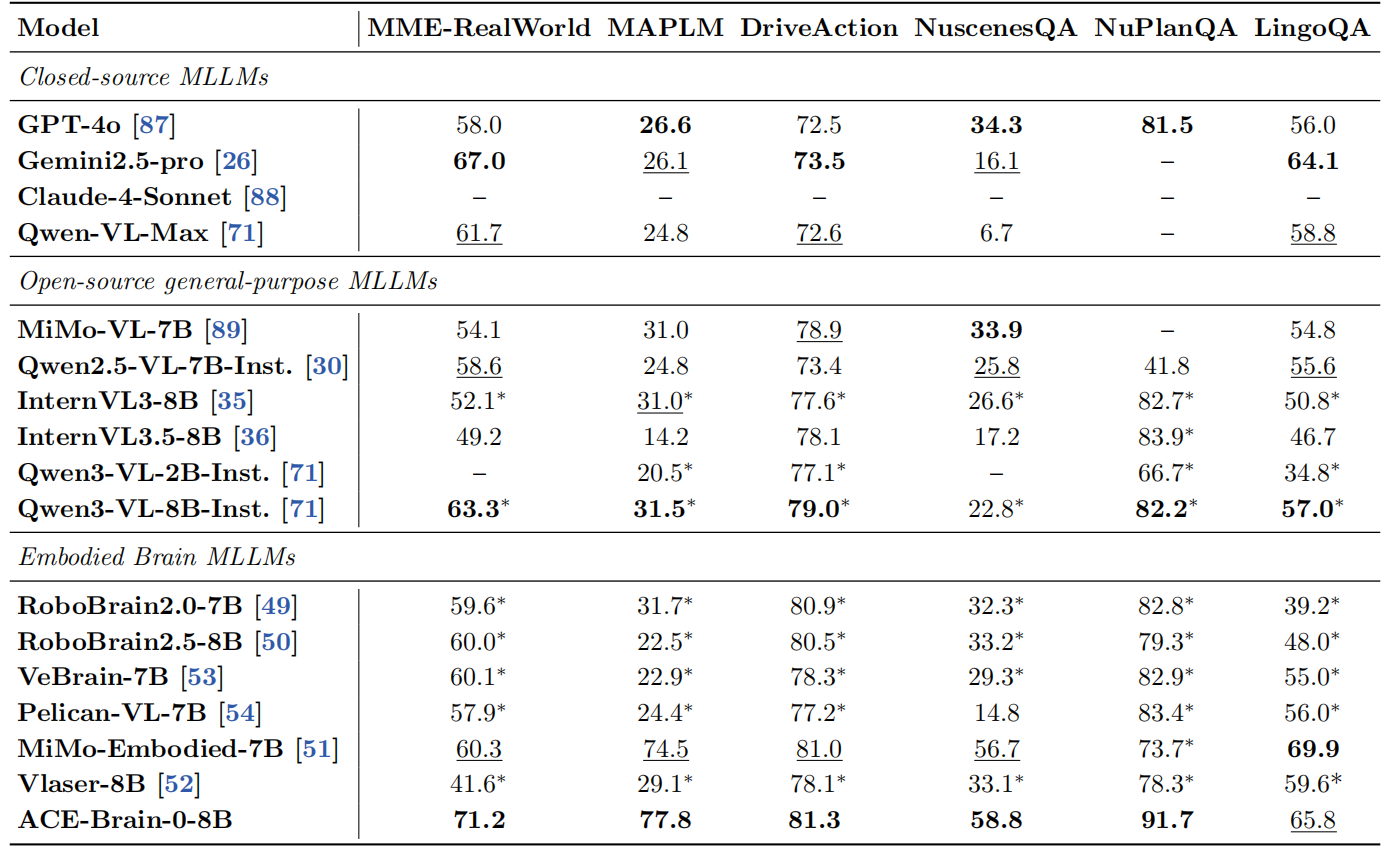
*代表基于上述模型复现/下划线代表次优表现/黑体代表最优表现
低空感知领域:
ACE-Brain-0在5个低空视觉benchmark上均取得显著领先表现,包括UrbanVideo-Bench(城市级无人机场景理解)AirCopBench(空中交通关系理解和多无人机视角协同理解)、AVI-Math(空中几何推理与数值计算)、Airspatial-VQA(低空空间视觉问答)、HIRVQA(遥感视觉问答),尤其在城市级无人机场景理解(UrbanVideo-Bench)和空中交通关系推理(AirCopBench) 等关键能力上实现大幅提升。
其中UrbanVideo-Bench(城市级无人机场景理解)主要评估模型在城市级无人机视频中的大尺度场景理解与地标识别能力。ACE-Brain-0以56.9%的成绩,相比当前最强具身大脑模型相对提升51.7%。
AirCopBench(空中交通关系理解和多无人机视角协同理解)主要考察模型在复杂城市道路拓扑下的空中交通监控与车辆关系推理能力。ACE-Brain-0以70.3%领跑具身模型,相比当前最强具身大脑模型相对提升35.4%。
AVI-Math(空中几何推理与数值计算)主要评估模型在无人机视角下进行 几何计算与结构化数值推理能力。ACE-Brain-0相比当前最强具身大脑模型提升1.3个百分点,达35.0%。
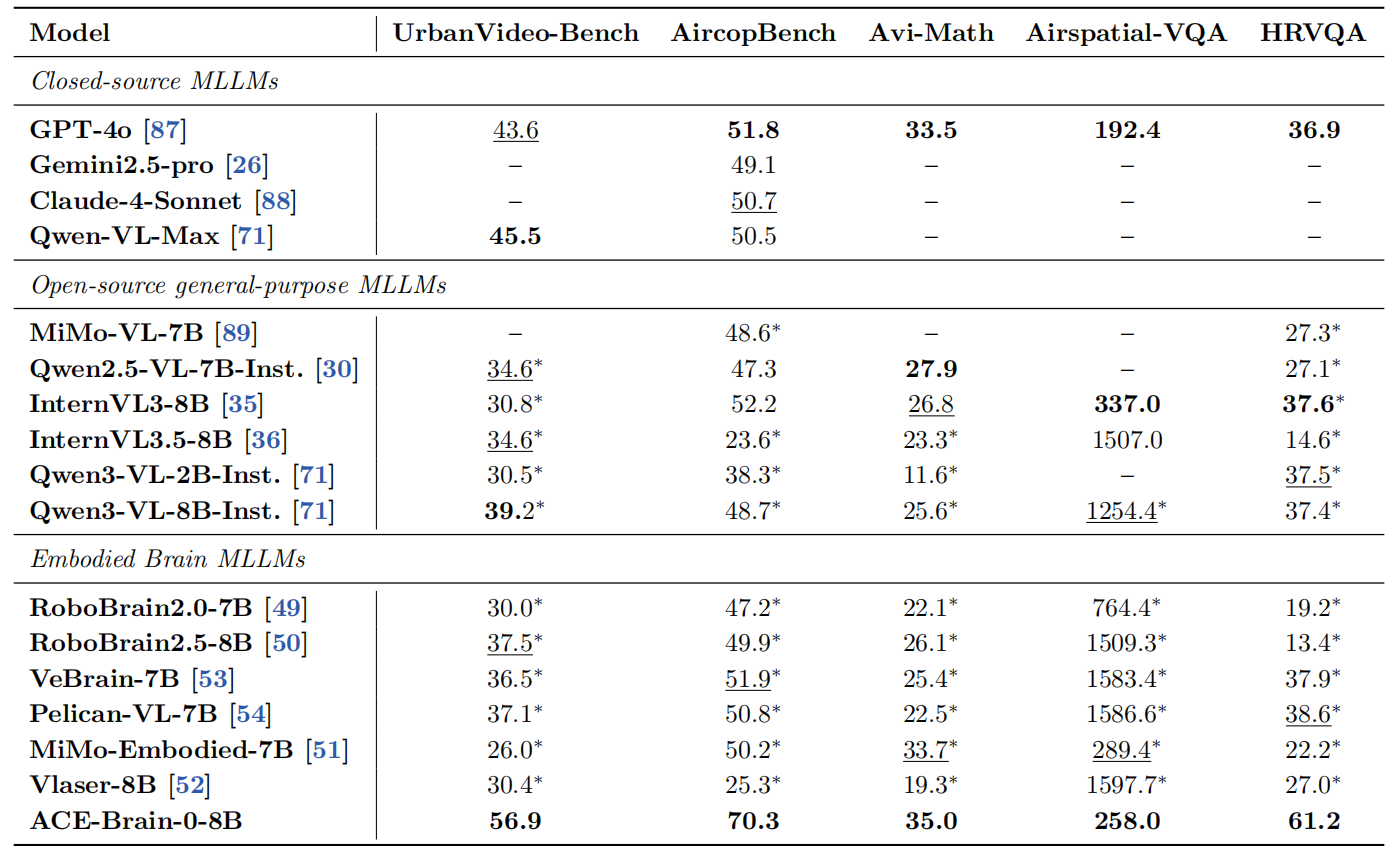
*代表基于上述模型复现/下划线代表次优表现/黑体代表最优表现
具身交互领域:
ACE-Brain-0在4个具身benchmark上均表现出稳定优势,包括RoboVQA(机器人操作理解)、EmbSpatial(具身空间理解)、EgoPlan-Bench2(具身任务规划)、EB-Habitat(具身导航理解),尤其在机器人操作理解(RoboVQA)等关键能力上实现显著突破
RoboVQA(机器人操作理解)主要评估模型对机器人操作行为与物体交互过程的理解能力。ACE-Brain-0以64.6%的成绩远超同类模型。
EmbSpatial(具身空间理解)主要评估模型在具身环境中的 空间关系理解与环境结构认知能力。ACE-Brain-0成绩达77.3%,相比当前最强具身大脑模型提升1个百分点。
EgoPlan-Bench2(具身任务规划)主要考察模型在第一视角复杂任务中的长时序任务规划能力。ACE-Brain-0成绩达55.3%,相比当前最强具身大脑模型提升1.9个百分点。
EB-Habitat(具身导航理解)主要考察模型在仿真具身环境中的导航决策与完成完整任务的综合能力。ACE-Brain-0成绩达42.3%,相比当前最强具身大脑模型提升2.3个百分点。
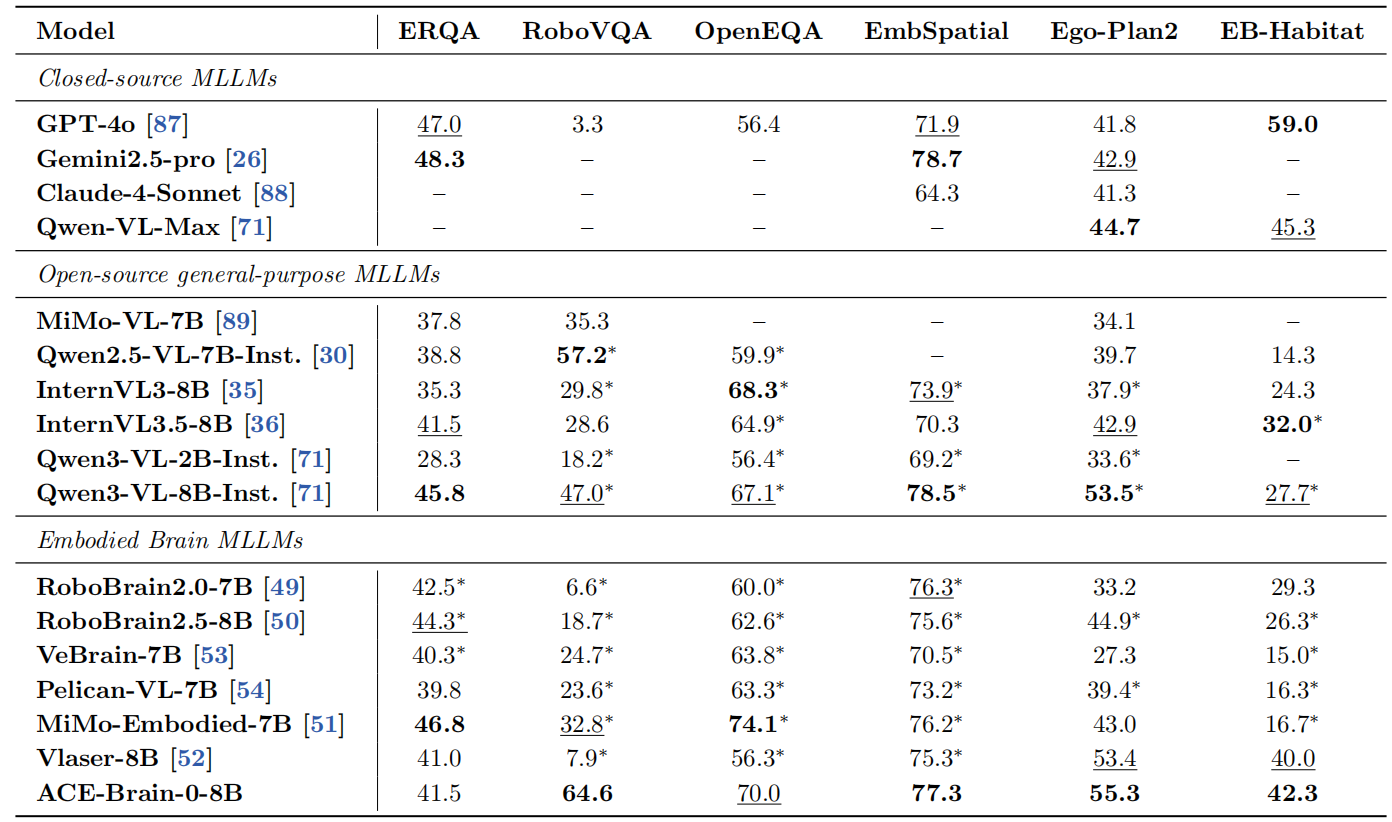
*代表基于上述模型复现/下划线代表次优表现/黑体代表最优表现
▎共享空间智能成为具身智能新世界观
一个模型,一套参数同时在这些任务上的卓越表现非常有意义。它说明“空间优先”不是一句漂亮口号,而是会真实改变跨形态学习效果的设计原则。尤其是具身交互那条曲线更耐人寻味:为什么直接学会失败,而先学空间再学会成功?直观上看,因为当智能体面对真实世界时,动作策略往往依赖于对环境结构的正确理解。如果连空间关系都没有稳定学会,那么所谓“具身能力”就很容易变成表面模仿;反过来,如果先掌握了共享的空间骨架,再去学具体动作,就像先学会看地图再学开车,很多问题会突然迎刃而解。
更重要的是,报告并没有满足于“实验上可行”,还试图回答:为什么空间真的适合做共同底座? 在附录理论部分,报告把这个想法形式化为一个“可恢复的空间scaffold”:模型的内部表示中,应该存在一个形态无关的共享几何变量,它承载三维布局、相对位姿、深度和拓扑等信息。如果训练后这个共享变量能够被稳定“解码”出来,那么它就不再只是一个模糊特征,而会变成跨不同身体都能复用的空间核心。理论中进一步指出,后续不同系统需要学习的,更多会是各自身体特有的感知、动力学和控制部分,而不是反复从零学习几何世界。
这套理论把一个深奥问题讲清楚了:为什么是“空间”,而不是别的? 因为空间不是一个普通任务,它更像是所有物理智能共同依赖的坐标系。无论是车在车道中判断前后左右,还是无人机从鸟瞰视角推理道路关系,还是机器人在房间里判断物体位置,它们都必须先拥有一种内部“空间地图”。ACE-Brain-0就是把这种“内部地图”从隐含假设提升成了方法设计的起点。
这一技术路径的领先性,不仅在于解决了当前具身AI 的核心痛点,更在于为未来通用物理世界智能的研发提供了可复用的底层框架。ACE-Brain 真正让人兴奋的地方,不是某一个分数超过了谁,而是它重新定义了“通用具身智能”应该从哪里开始。过去我们常常把“通用”理解为一个模型会做很多任务;而 ACE-Brain 让人看到另一种可能:真正的“通用”,或许不是任务列表越来越长,而是先找到这些任务背后的共享结构。空间,就是它给出的答案。ACE-Brain提出了一种新的具身智能世界观:不同身体不一定要从头学起,它们可以先共享一个关于世界的空间理解,再在这个基础上长出各自的能力。未来的具身智能体,无需再为单一形态定制模型,只需基于ACE-Brain的空间智能底座,就能快速适配新的物理本体与应用场景。从自动驾驶到低空经济,从工业机器人到家庭服务设备,展现出面向真实物理世界多场景的平台潜力。
该技术成果已上传:
https://arxiv.org/abs/2603.03198
Project Page:
https://ace-brain-team.github.io/ACE-Brain-0
Code:
https://github.com/ACE-BRAIN-Team/ACE-Brain-0
Hugging Face:
https://huggingface.co/ACE-Brain/ACE-Brain-0-8B
附注:
大晓机器人于2025年12月28日正式重磅推出具身超级大脑模组A1。凭借首创以端到端为核心的自主空间智能,依托模型的视觉理解和运动规划能力,搭载具身超级模组A1的机器人能实现动态环境下鲁棒、安全、合理的路径生成,真正实现“自主行动”。
大晓机器人团队基于纯视觉感知与端到端的深厚技术积累,创新性地将高精度视觉感知能力迁移至具身智能场景,打造出行业领先的纯视觉无图端到端VLA模型,为具身智能超级大脑模组 A1 赋予了“看环境、想路径、避障碍,换环境照样行”的核心能力。
具身超级大脑模组A1具备拥有云端交互能力,依托云端模型平台,能实时解析自然语言指令与图像语义的意图关系,像人一样理解复杂的现实世界,生成可执行的中间指令(如“前进50厘米““绕过障碍”“靠近目标”),再由底层控制器精确执行。这使得机器狗不仅能够在复杂环境中完成自主巡检、跟随、避障等多样任务,而且能根据自然语言指令精准完成任务。
基于以上优势,具身超级大脑模组A1在安防、能源、交通、文旅等对设备可靠性要求极高的场景中,可实现长期稳定工作,让具身智能真正具备了走进产业一线的实用价值。

2025年,人形机器人产业迎来爆发拐点。特斯拉Optimus量产在即,华为、宇树等企业加速技术突破,行业正从“实验室研发”向“规模化落地”跃迁为打通产业链上下游协作壁垒,艾邦机器人正式组建"人形机器人全产业链交流群",覆盖金属材料、复合材料、传感器、电机、减速器等全硬件环节,助力企业精准对接资源、共享前沿技术!
扫码关注公众号,底部菜单申请进群
