
在具身智能的浪潮中,关于“大模型应该如何指导机器人行动”的探讨从未停歇。是赋予模型强大的语义理解与泛化能力(VLA),还是让它拥有对物理世界的“想象力”与动力学预测能力(世界动作模型)?这不仅是学术界的争论焦点,更是决定下一代机器人技术路线的战略抉择。
在 2026 第八届北京智源大会上,星海图首席科学家赵行给出了来自前沿一线的深度思考。他系统分享了星海图团队在“自回归 VLA”与“世界动作模型”两条技术路线上的探索与验证,并重点解读了星海图最新开源的 G0.5 基础模型——为何它能一举刷新 7 个全球评测榜单 SOTA 纪录,尤其是在业界公认难度最高、最贴近真实家居长程交互的 BEHAVIOR-1K 长时序移动操作基准上,以单一通用模型碾压传统多模型集成冠军方案、实现断层领先,其背后的核心技术逻辑究竟是什么。以下为赵行在智源大会上的演讲全文整理。
VLA还是WAM?今年最受关注的路线之争
在具身智能领域,今年大家特别关注的一个问题是:到底是 VLA 更好,还是 WAM 更好?这也是今天我分享的内容——两个模型的故事:VLA 和 WAM。
如果只看名字,VLA 和 WAM 差异很大,但深入到模型架构上进行对比,它们的输入都是视觉和语言,输出都是动作,模型结构上其实也非常相似,都由 Transformer 的架构构成。过去几年,星海图在这两个技术上都有一定的技术探索,今天我想讲讲我的思考。

为什么我们还在“下注”自回归VLA?
过去 VLA 的主流做法,是在现有的 VLM 上加一个 diffusion head 进行模型训练,来形成以 diffusion 生成动作为主的 VLA 模型。
但在更早期,VLA 其实已经有经历过 RT-1、RT-2、OpenVLA 这样的纯自回归模型,只是这个技术路线在过去几年并不是特别成功。直到 π0、π0.5 出现之后,行业逐渐都转向以 diffusion 为主导的 VLA 模型。
但是我们的判断是,自回归的 VLA 模型仍然值得我们再做一次下注。有三个原因:
第一,过去包括 Pi-FAST 的工作已经证明,自回归模型有更快的训练方法和收敛速度。
第二,一旦采用自回归的方式,就可以复用过去在语言模型和视觉语言模型里的发展成果,比如思维链、in-context learning、 steering 这些能力。
第三,自回归模型经过语言模型的预训练之后,可以有零样本的语义泛化能力。
这些都是在扩散模型 DiT 里很少看到的。

但是在自回归的 VLA 里有一个过去一直被大家忽视的很重要的部件,叫做 action tokenizer。我们关注它的原因是:语言天生就是离散的,通过自回归的方法可以自然而然地一个token、一个token地输出。但是动作不一样,动作和视觉更像,是由连续的信号来做机器人的控制。
要让语言模型也能输出动作,本质上像是让语言模型学习另外一门外语。这就要求我们先解决一个问题——怎么把连续的动作信号变成离散的动作信号,使得它能够和语言模型一起进行训练。
围绕这个问题我们做了一系列工作:
1、从 FAST 到 FASTer:动作 Tokenizer 的第一次迭代
我们观察了过去把连续动作变成离散 token 的几类方法:
第一是直接把动作数值做量化,变成一些离散的 token,但这样往往会带来非常冗余的动作序列。
第二是采用 VAE、VQVAE 这类神经网络的方式,获得离散的动作 token,但是这样的方法往往会带来比较差的重建精度。
最相关的工作是 FAST,这种方法在频率上做量化,算法和图像压缩里的 JPEG 压缩算法非常相似,不同的图片有不同的信息量,动作也是,复杂的动作会被压缩为更长的序列,简单的动作会被压缩成更短的序列。那么我们是否有一个更好的方式管理这种变长序列的编码?
为此我们提出了 FASTer:把机器人的动作空间在时间维度展开和自由度维度上展开,得到一个二维矩阵,再像处理图像一样对这个矩阵分组,用 VQ、RVQ 等方法做压缩和量化,最后同时在时域和频域上重建精度。将 FASTerVQ 接入到现有的主流 VLA 模型上,可以得到很高的控制频率和更强的模型效果,并且这样的 tokenizer 也可以和任意的 VLA Backbone 进行结合。
2、跳出重建精度:用条件熵重新定义“好”的Tokenizer
接下来,我们进一步思考了 action tokenizer 的问题,从头出发——action tokenizer 最终想要解决什么问题?过去我们关注的问题是否过于简化或者过于片面了?
过去的 action tokenizer 主要关注的是重建,并没有真正关注 tokenizer 对于模型训练有多大的帮助。简单来说,过去关注的是在 tokenizer 进行动作压缩和解压缩以后,动作重建精度怎么样。但如果思考如何让模型更好地学习我们的动作,就会发现更重要的是去优化一个条件熵的目标。可以拆解为以下几个维度:
维度一:稳定性。当输入的动作轨迹有一些小的扰动,压缩以后序列的变化应该尽量小、足够稳定。
维度二:容量。一个好的压缩器,最终的词表大小以及序列长度应该是合理的、有限且非常小的。图像压缩能轻松实现50~100倍的压缩率,视频压缩能高效实现100~1000倍。对于动作来说,我们的期待是能够很容易实现10~50倍的压缩率。
维度三:语义对齐。动作不是凭空存在的,所有动作都会和物体与环境进行交互,因此它应该要和语义进行对齐。
维度四:跨本体迁移。我们设计的 tokenizer 希望适用于任何构型的机器人。

围绕上述四个目标,我们设计了 ActionCodec。
我们的模型架构设计参考了 Perceiver 的思路。具体来说有两个输入:第一个输入叫 soft prompt,可以用自然语言告诉模型当前机器人的名字、ID 、控制频率、输入序列长度,以及正在执行的任务和所属的数据集;第二个输入是有 time step 的 frequency embedding,也就是说加上时间上的位置编码,能够使模型很好地理解现在输入的序列信号。
把这两个信号全部压缩到 Perceiver 的 Transformer 模型里去,最后输出一个定长的 action token。
这个 ActionCodec 模型训练的 loss 也有多个目标,对应了需要优化的方向,分别是重建的 loss,在时间上有一些抖动后编码的变化非常小,还有用来对齐语义的 CLIP loss,最后再加上一些其他的 regularization。
这套 ActionCodec 既满足了熵的最小化,同时也可以实现比较高的轨迹重建精度。在实验中,我们发现它的表现超过了过去所有的 action tokenizer。在此基础上,星海图催生了新一代 VLA 基座模型 G0.5。
G0.5:星海图的VLA基础模型答卷
视频中我们给大家展示的所有 demo 都是零样本,也就是模型只经过预训练,没有经过任何后训练就能展示出的能力。为了让模型表现出这样的能力,人类要做的就是 prompt engineering,或者说是 steering,通过键盘输入,把各种动词、被操作物体组合成句子,让模型完成这一系列长程的任务。
G0.5 模型架构是什么?说起来非常简单,就是把 VLM 直接加入新的动作词表以后变成一个 VLA,这个模型相比过去的 VLA 模型不再使用额外的 action head。π0.5 会用额外的action expert 去进行训练,而我们的做法是把动作变为一门外语去教语言模型进行输出,只有一套 VLA 的参数,这套参数同时完成了视觉处理、语言处理、推理处理和最后的动作输出。
在自回归离散的 VLA 里最重要的设计就是 action tokenizer,G0.5 里使用的 tokenizer 就是 ActionCodec,最后解码以后可以输出一个 27 维的 unified action space,对于任何机器人的构型都适用。这个模型让机器人做一个任务,可以自己做内在的 CoT,包括 subtask 的分解、bounding box 物体的检测、2D 的 motion planning、2D trace,以及 action hint。比如,为了把毛巾放进水池并且把水龙头打开,模型输出了机器人控制信号,比如 left control 和 left gripper。人形机器人有上百个关节,我们的模型不一定要自回归输出每个关节的动作,如果这个关节现在不需要动,就不进行输出。比如在这个例子里就 drop 掉了右手的动作。
很多人说自回归模型会不会输出非常慢?不像 diffusion model 可以把整个动作一起进行 denoising。我们的答案:其实不是的。自回归模型有很多可以优化的空间,可以对不动的关节不进行输出,可以用语言模型里比如投机采样的方法进一步加速。实验结果表明,我们可以把 VLA 模型优化到小几百毫秒的推理速度。
G0.5 是一个预训练基座模型,在 7 个基准上都达到了非常好的效果。在这些 Benchmark 里我最喜欢的一个是 BEHAVIOR-1K。
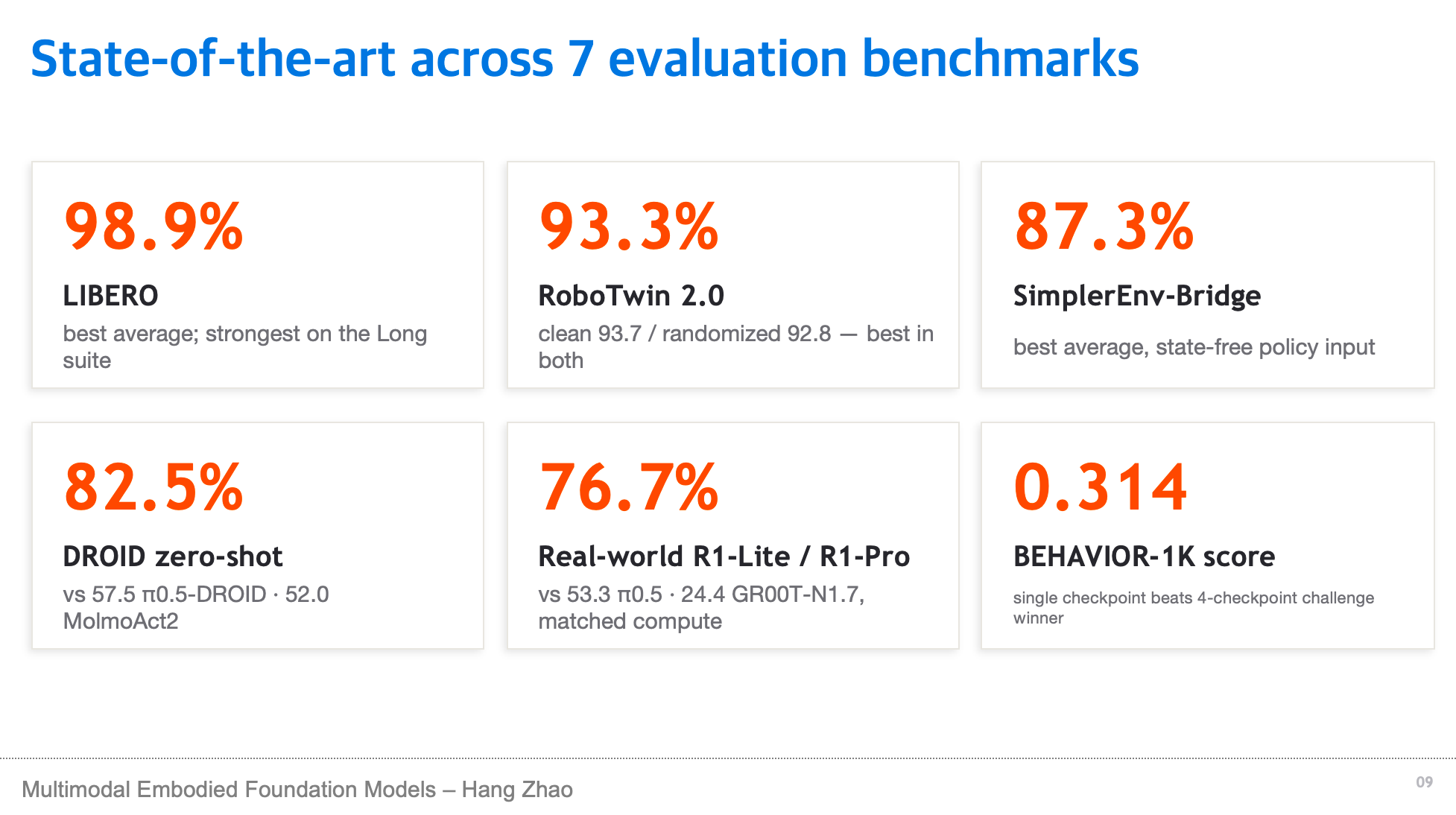
BEHAVIOR-1K 是斯坦福李飞飞实验室推出的机器人评测平台,是一个大规模的数据集,里面包含着非常多普通人日常想要机器人干的任务。他们发放调查问卷,询问“你希望机器人在家里做什么”,基于这样的问卷结果,构建出一个数据集以及 Benchmark。G0.5 模型可以在这个 Benchmark 里做非常复杂的长程任务,比如复杂的桌面整理、洗衣间整理等。所有效果都只是在 G0.5 基础模型上进行了一次简单的微调。
BEHAVIOR-1K 长时序家居自主移动操作视频
(仿真默认低分辨率渲染,视频已作超分画质增强)
再看WAM:视频生成真的必要吗?
世界动作模型在这个方向上的开篇性工作叫做 UniPi。它的思路是:图像生成模型先生成一张未来的图像,基于此去解机器人的 IDM(逆动力学模型),最后让机器人执行这个动作。这样的好处是,如果视频生成模型是泛化的,就意味着最后输出的动作也是泛化的。这种方法的缺点是如果生成视频图像质量很糟糕,最后生成动作的质量也会变得很糟糕。这是所有非端到端或者拼接式模型的共同缺点。
今年技术的转变,包括 DreamZero、LingBot-VA 这样的工作率先提出了我们可以把视频生成模型后面接一个 action expert,让它们共同用 diffusion transformer 的方法进行模型训练,就能得到端到端的机器人模型。
这样的模型架构和 diffusion VLA 非常相似——在已有的一套基于视觉语言模型的 foundation model 上加一个 expert,而 WAM 是在已有的视频生成模型上加一个 expert,大家都想做寄生模型,这样的模型效果很好,是因为视频生成模型里原本就已经学到了很多空间泛化、时间泛化、动力学泛化。但是这类模型有一个重要的不足,就是它们依托于视频生成模型,而生成视频往往耗时较长。
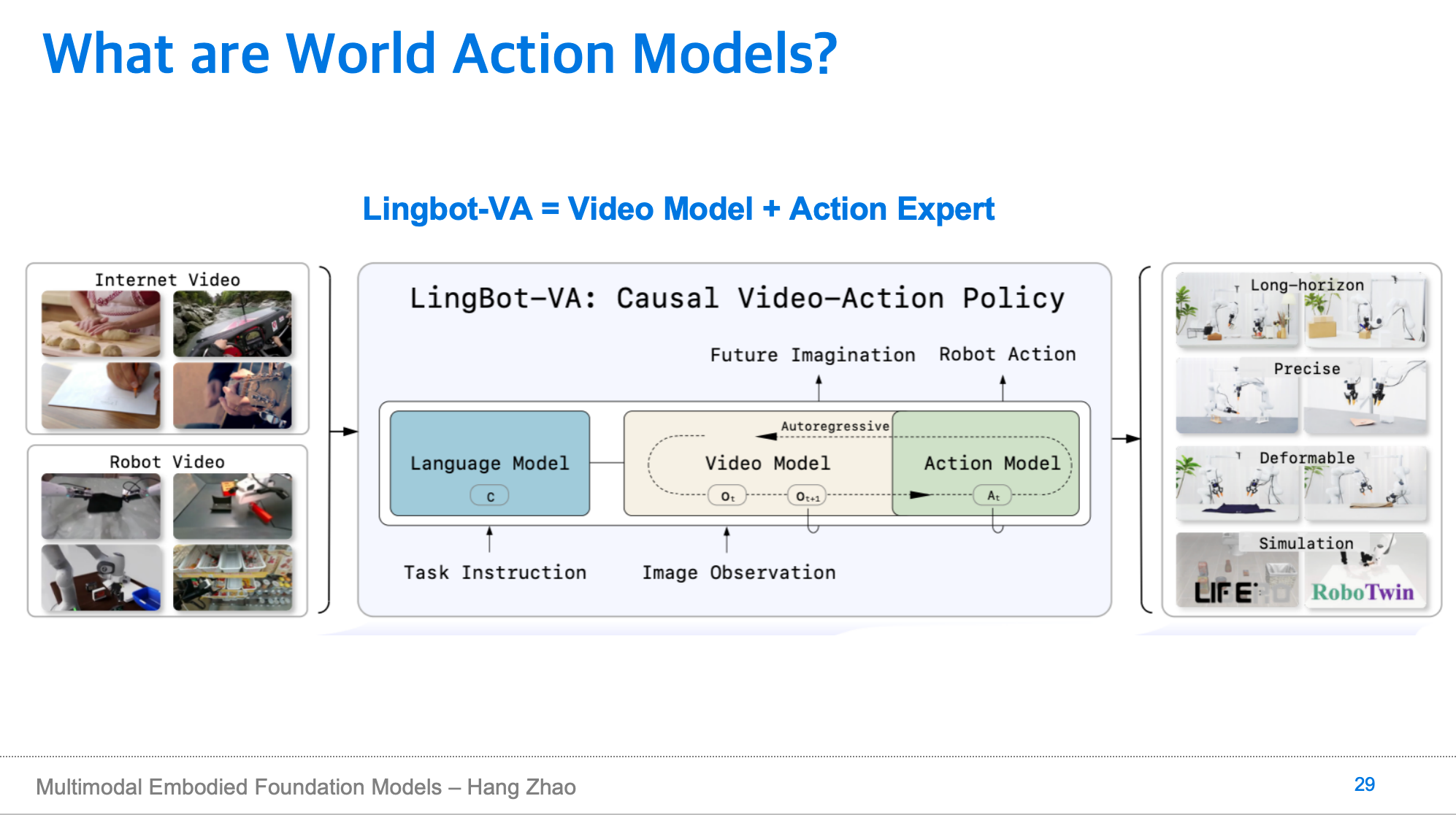
所以在最近工作中,我们重新思考生成未来视频在 WAM 里的作用,简单拆解为两个维度进行探究:
1、视频生成监督在训练时是否帮助我们学到了更好的表征?
2、在模型推理时,视频生成是否帮助我们更精准地预测到了未来,并且 IDM 基于未来预测出来的视频解出了更好的动作?
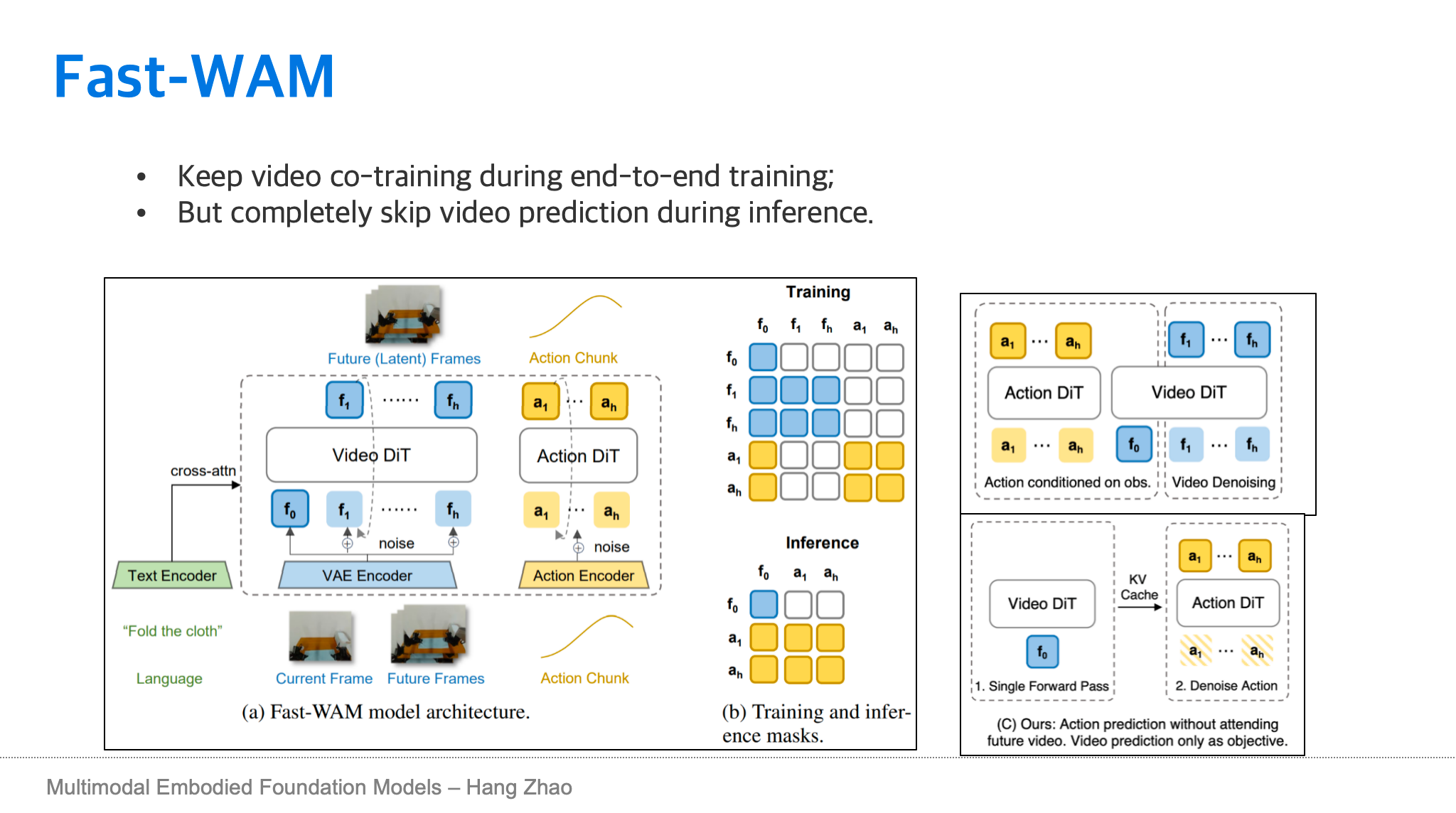
我认为 representation 更重要,过去大多数做计算机视觉研究的学者也都会认为,图像生成的结果并没有那么重要,神经网络核心是在学一个好的表征。如果这个答案是正确的话,那么视频生成这个步骤和 VLA 模型训练里的 co-training objective 其实非常相似。在 VLA 训练中,不仅要学习 VLA 输出最后的轨迹动作,同时也会让它学习一些 bounding box 的预测,让它去预测 subtask 的分解。在 WAM 里,虽然最终目标是去学习动作,但是学习未来的视频能够更好地帮助模型去学习未来会发生什么事情,而未来发生这个事情的潜在动作 latent action 和机器人能执行的 explicit action 其实是紧密相关的。
做了很多实验以后,我们发现世界动作模型的本质是在学习隐式的表征,而在推理时显示预测未来只会大幅浪费算力。我们修改模型训练中的 attention mask,并且在推理时不再去显示预测未来的视频,能够大幅提升世界动作模型的推理速度,模型是否在推理时预测未来的视频其实并不关键。
展望:VLA与WAM不是替代方案,而是走向融合
总结一下今天分享的内容:
第一,在 VLA 方向,我们认为 VLA 有非常强大的语义泛化能力,并且把过去的动作专家去掉,从而构建一个原生自回归的 VLA 模型,能达到非常强的泛化能力。
第二,世界动作模型当下非常火的话题,但预测未来的视频可能并不是必要项。
从未来看,这两条技术路线不是一个相互取代的关系,我们认为VLA和世界模型各有各的优势,未来的方向大概率是 VLA 的语义能力和泛化能力与世界动作模型的空间和动力学能力结合在一起,形成一个统一的模型。
当下也有一些技术的进展,比如最近发布的 Cosmos3,也尝试把 VLA 和世界模型进行 mixture of transformer 的拼接,它已经展现出了非常强大的效果。我相信未来能找到比 Cosmos3 更加统一的、性能更好的,并且更高效的一个模型架构。
谢谢大家!
2025年,人形机器人产业迎来爆发拐点。特斯拉Optimus量产在即,华为、宇树等企业加速技术突破,行业正从“实验室研发”向“规模化落地”跃迁为打通产业链上下游协作壁垒,艾邦机器人正式组建"人形机器人全产业链交流群",覆盖金属材料、复合材料、传感器、电机、减速器等全硬件环节,助力企业精准对接资源、共享前沿技术!
扫码关注公众号,底部菜单申请进群
