
自变量机器人发布跨具身动作分词器 X-Tokenizer,将 VLA 中的动作离散化从单一的“压缩-重建”问题,重新定义为“多模态推理与动作之间的语义接口学习”问题。
动作分词器决定了拆分出的动作 Token 是否具有语义,是否能加速预训练模型的收敛,从而最终影响了 VLA 模型输出连续动作的性能。这是自变量机器人的最新发现。
具身智能的 VLA 模型(视觉-语言-动作模型)是将预训练的 VLM 模型(视觉语言模型)与动作专家(Action Expert)连接起来,前者接收图像和语言指令,输出隐藏状态;后者则将隐藏状态转化为机器人可以执行的连续动作指令。但两者的表示方法存在不匹配:VLM 模型输出离散表示,而机器人需要接收连续指令。在预训练时,需要利用动作分词器(Action Tokenizer)来将连续动作拆分压缩为离散表示。
对此,自变量机器人提出一种新的轻量级、跨具身动作分词器 X-Tokenizer。它采用“编码器-语义残差量化(SRQ)-解码器”架构,用 SRQ 替换了传统的标准残差向量量化(RVQ),在这一层分离出动作意图,并在涵盖 17 个机械臂系列的 240 万条轨迹(包含 20 亿动作帧)上进行了预训练。
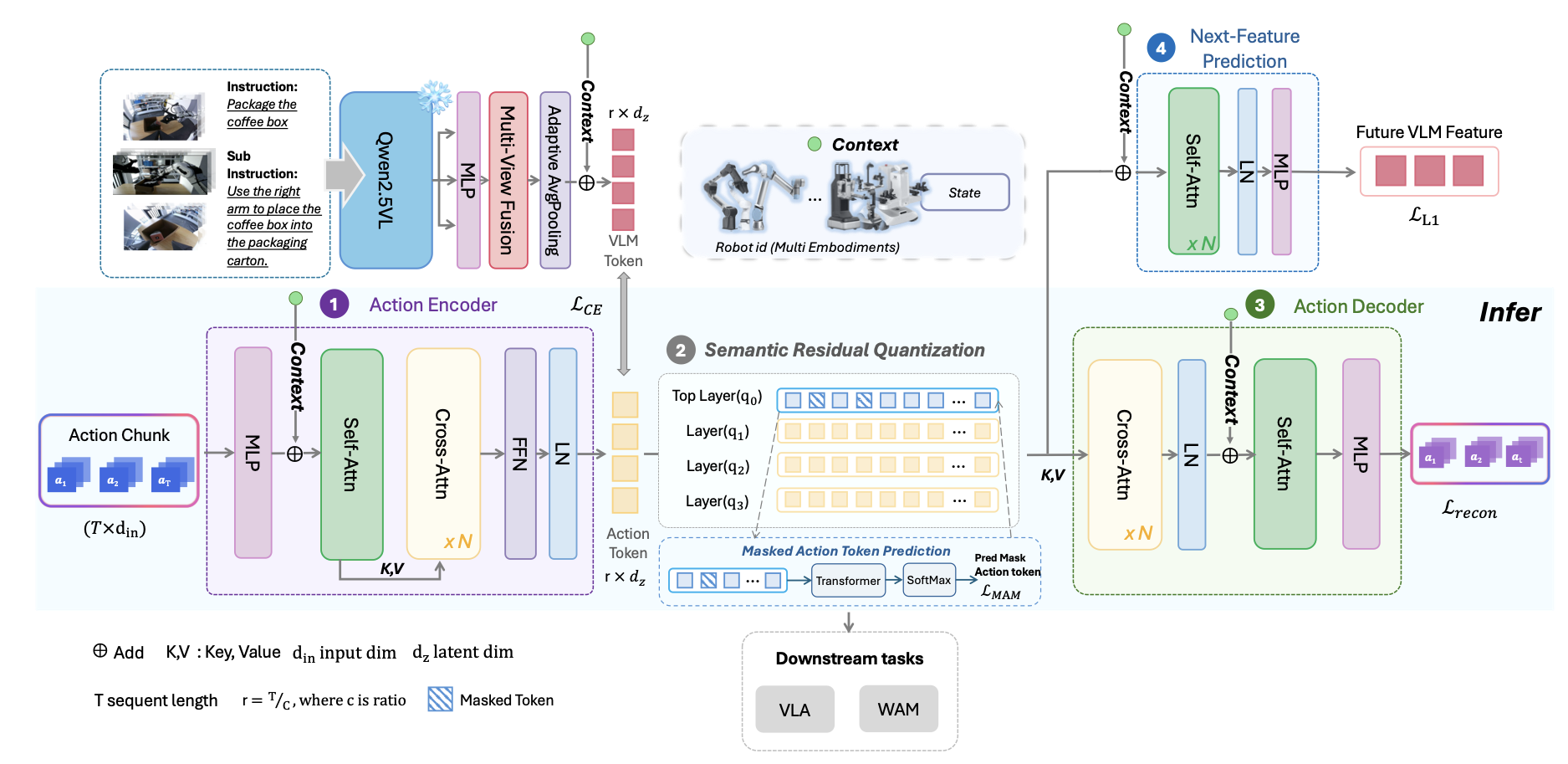
不同于 FAST、VQ-BeT 等以最小化重建误差为唯一目标的传统分词器,X-Tokenizer 在“编码器-语义残差量化(SRQ)-解码器”轻量架构之上,对残差量化施加监督:第一层通过掩码动作建模(MAM)学习粗粒度动作意图,形成离散动作语言;更深层级则保留细粒度几何残差。在此基础上,进一步引入与预训练 VLM 表征空间的对比对齐、以及未来帧视觉-语言特征预测两类跨模态监督信号,使动作 Token 在预训练阶段即与视觉、语言语义共享同一表示空间。
X-Tokenizer 在涵盖 17 个机械臂系列、240 万条轨迹上预训练后冻结,作为一个可复用的表示模块插入VLA 主干。实验显示,相比 FAST,多模态对齐能力提升 13.5%,长程任务性能提升 8.25%,RoboTwin 2.0 得分达到 82.8。这一结果表明了我们的核心观点,在 VLA 预训练中,动作分词器不应仅基于动作本身做压缩,而应基于其所处的多模态上下文进行设计——它的真正角色,是动作模态与视觉-语言模态之间的语义桥梁。
SRQ 捕获动作意图对齐语义,
抗噪声能力大幅提升
X-Tokenizer 采用 Encoder → SRQ → Decoder 的轻量级架构。其创新性的核心方法在于语义残差量化(SRQ),即在标准残差向量量化(RVQ)上施加非对称监督,让第一层能捕获到更多动作语义。
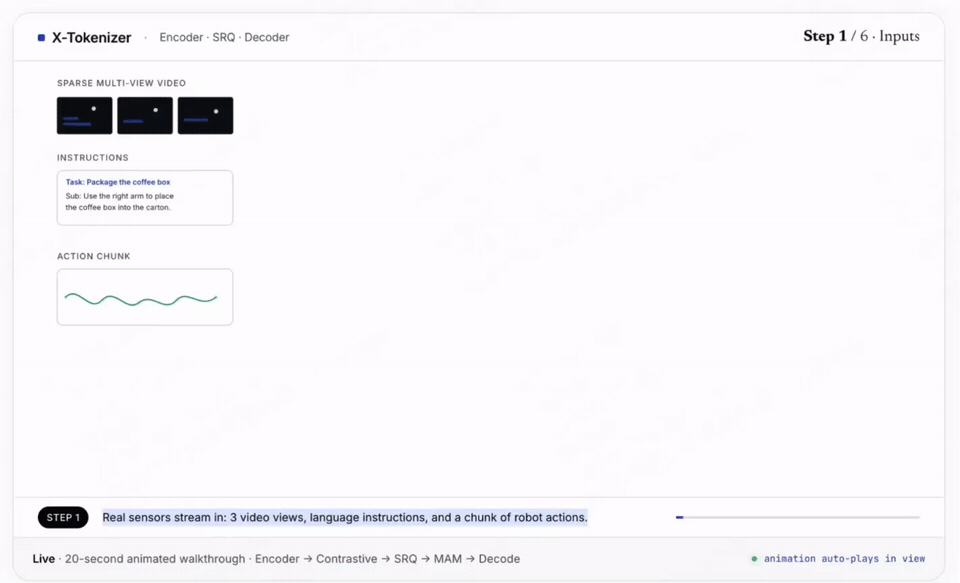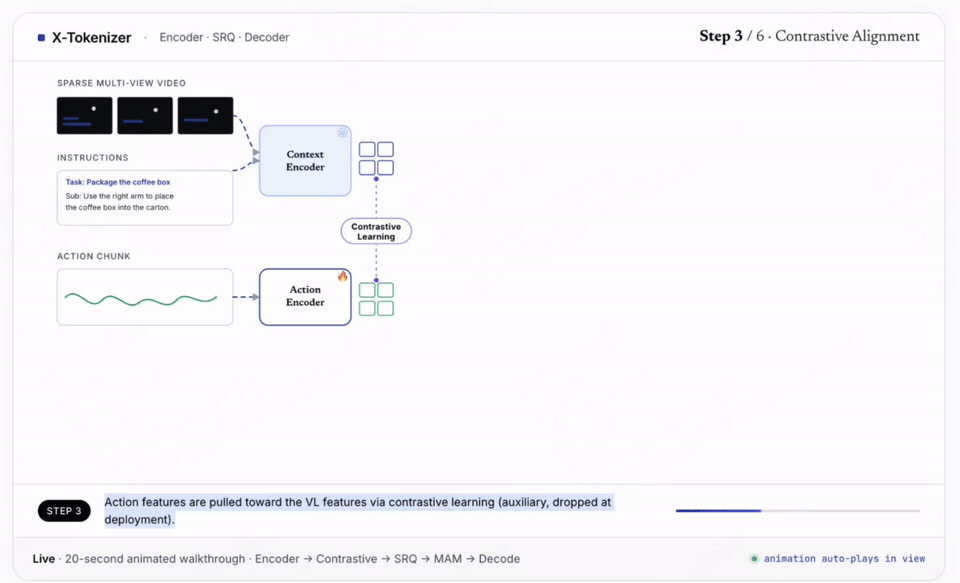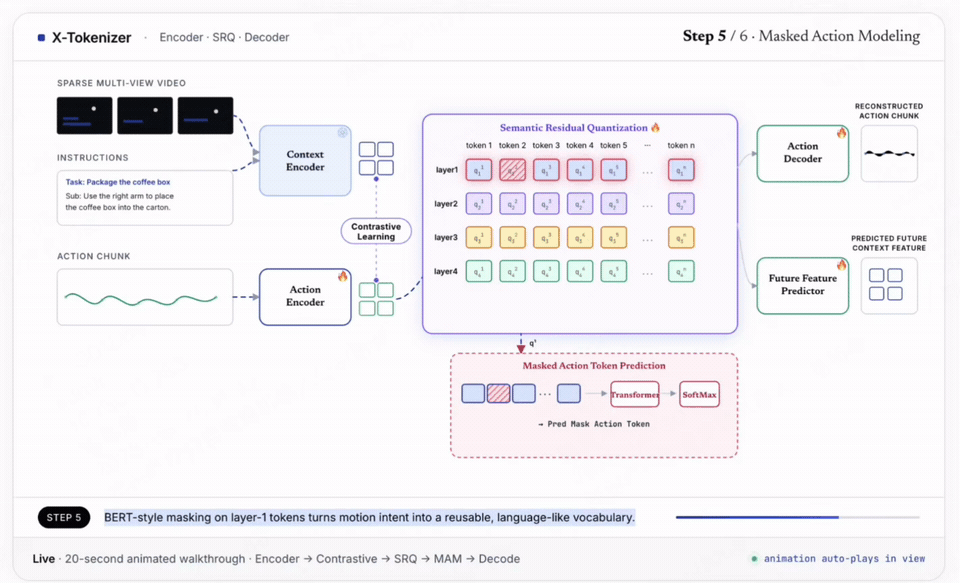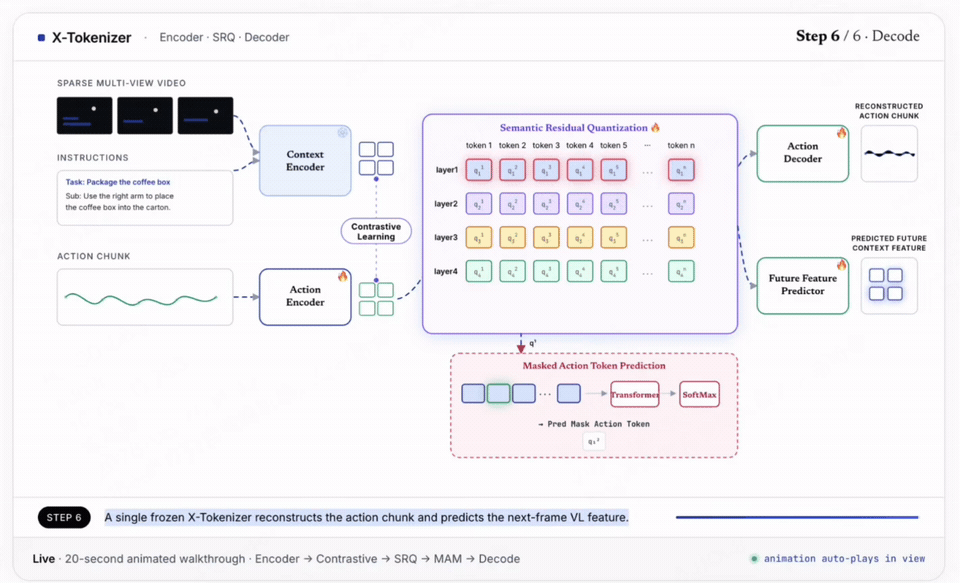
具体来说,传统的 RVQ 在重建动作时,所有层级看到相同的重建损失、趋向于均匀分配,拆分出的 Token 是纯几何的,没有特定动作语义。SRQ 则将粗粒度的动作意图和细粒度几何修正拆分,将它们分配到不同的 RVQ 层级,让第 1 层捕捉到更多动作语义,第 2-4 层保留更多重建细节。
通过引入掩码动作建模 (MAM)、Vision-Language Feature 对比对齐、下一帧Vision-Language Feature 预测三大语义监督信号,SRQ 网络实现了出色的效果:
当给动作注入噪声时,通过 SRQ 拆分的动作 ID 几乎保持不变,抗动作噪声鲁棒性(WER,越低越好)在 σ = 0.008 的噪声下为 0.526,说明噪声被第 2-4 层吸收,识别出的动作意图保持不变;而 FAST 的动作 ID 序列长度发生改变,WER 高达 1.445,说明无法区分主要动作与噪声,发生了语义反转。
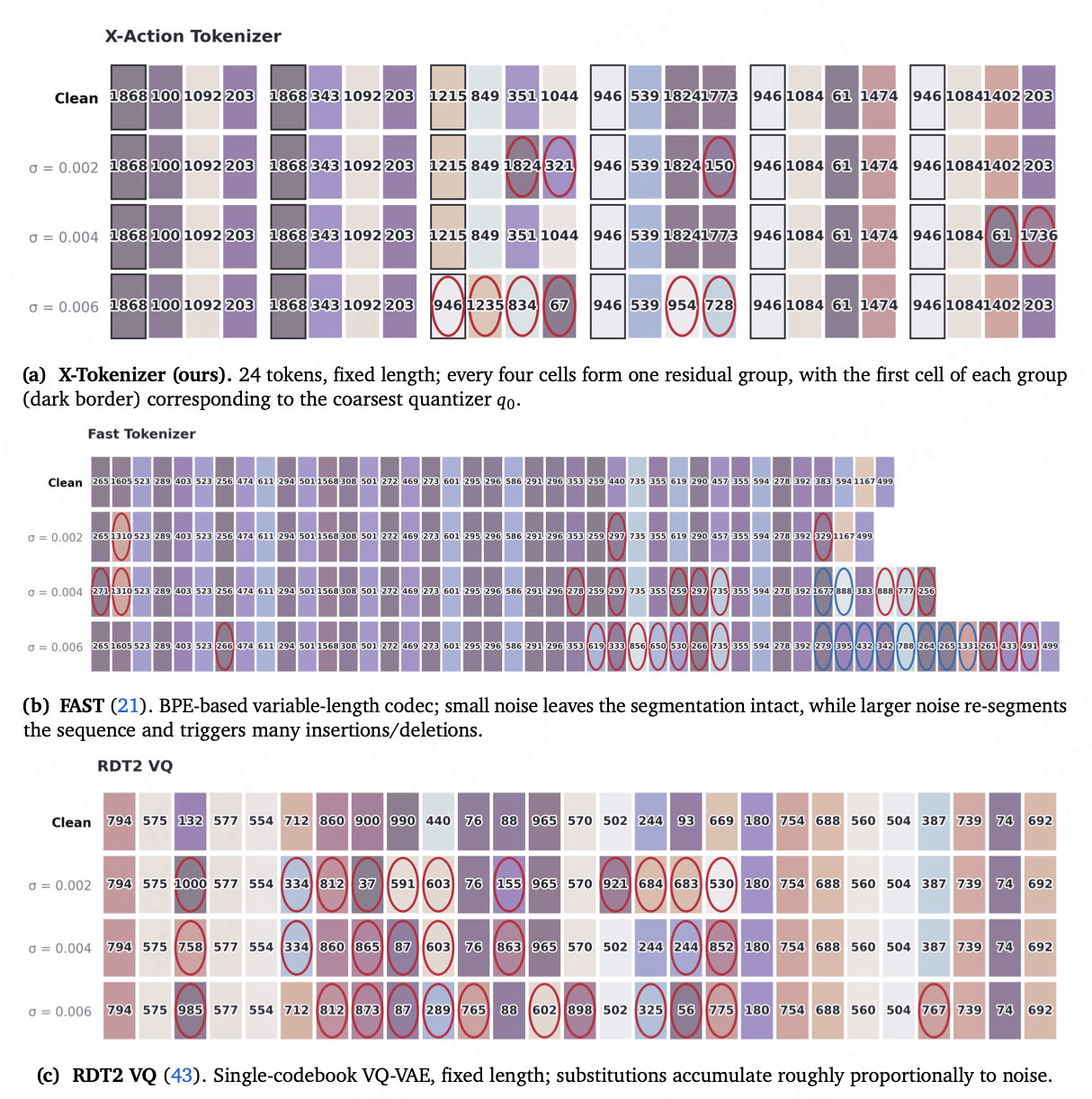
简单来说,X-Tokenizer 通过语义残差量化(SRQ)实现了实现语义-几何的分离,不仅使拆分出的动作 Token 具有明确的语义,并且能够抗动作噪声干扰。这些监督头仅在预训练时使用,在推理时移除,不会带来额外性能开销,而是将动作知识沉淀在 SRQ 网络结构中。
真机测试优于主流动作分词器,
长程任务成绩提升8.25%
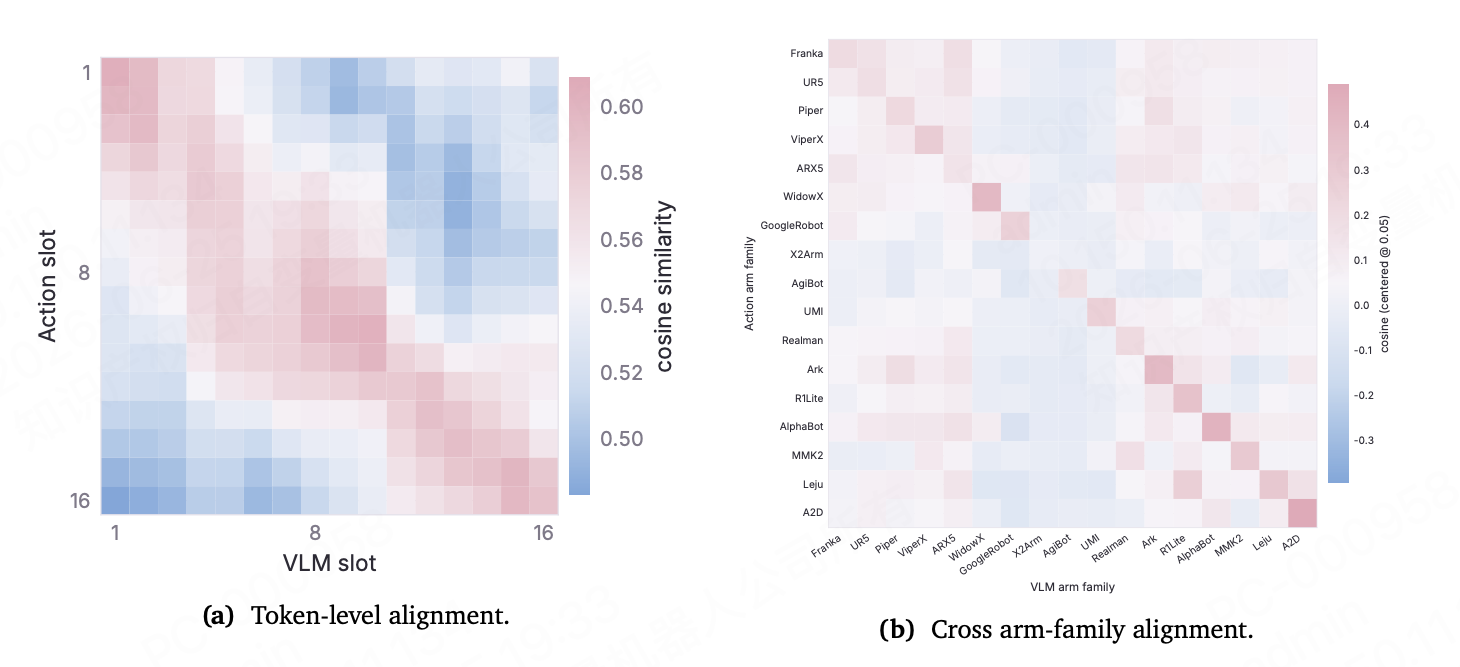
自变量对使用 X-Tokenizer 动作分词器的效果进行了实验。其将一段 64 帧的动作块压缩成 16 个 slot,每个对应一小段动作序列。此外,VLM 特征也被压缩到 16 个时间步。然后计算出两者的余弦相似度矩阵:呈现在对角线上的余弦相似度越高,说明同一个时间上,模型“看到”的视觉与“做出”的动作越匹配,动作模态与视觉模态越对齐。
可以看到,Slot 热力图中段余弦值峰值约为0.6,呈现出较高的相关性。此外多种机械臂的实验中,对角线均为正值,并且形态相似的机械臂之间有很强的相关性。这说明 VLM 模型确实学到了动作与视觉的语义对应关系,并且对于形态相似的机械臂能够共享知识。
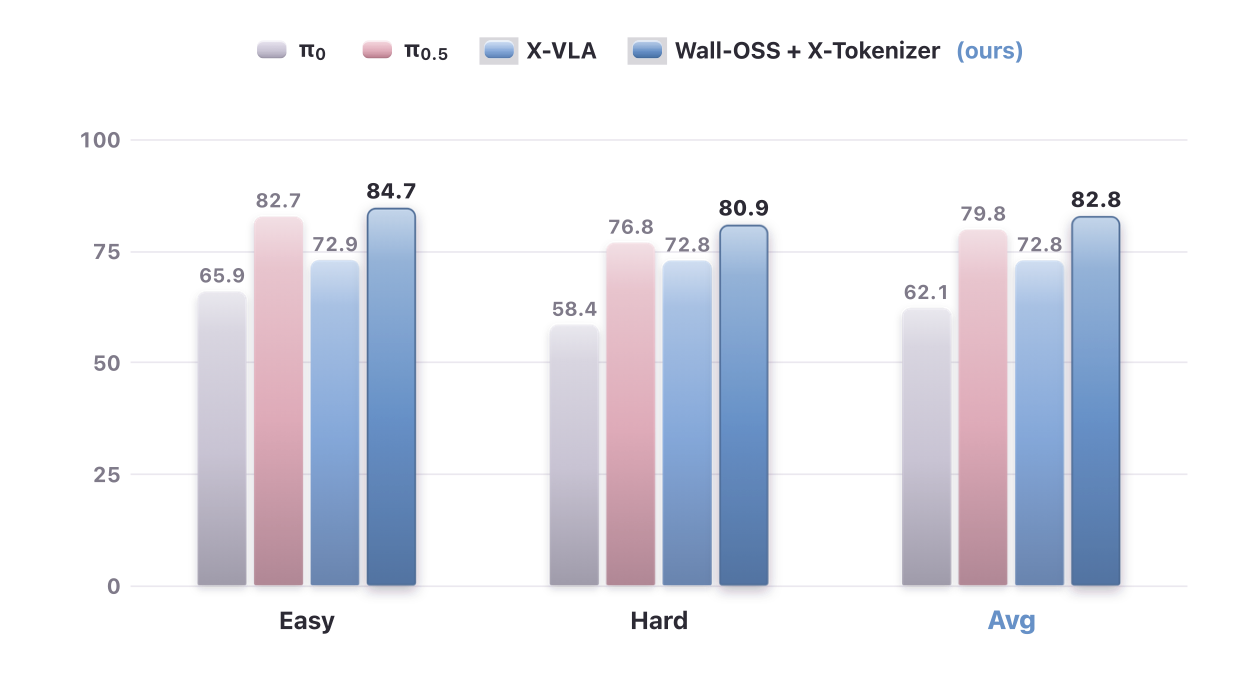
在 RoboTwin 2.0 基准评测上,使用WALL-OSS + X-Tokenizer ,测试成绩超过在简单和困难任务均超过业界主流模型 Pi 0、Pi 0.5 和 X-VLA。在困难任务中,WALL-OSS + X-Tokenizer 的分数更为领先,表明在视觉条件变化时,对齐动作与其他模态对完成任务更有用。
在真机测试任务里,X-Tokenizer 测试了7个桌面任务(5 个短期操作 + 2 个长程推理),并比较了四种动作分词方法:原始的 WALL-OSS 模型(未加动作分词器)、FAST动作分词器、仅重建动作的 4 级 RVQ 分词器,以及完整的 X-Tokenizer。结果表明,使用 X-Tokenizer 优于或打平其他方法,并且在长程推理任务有 8.25% 的提升。
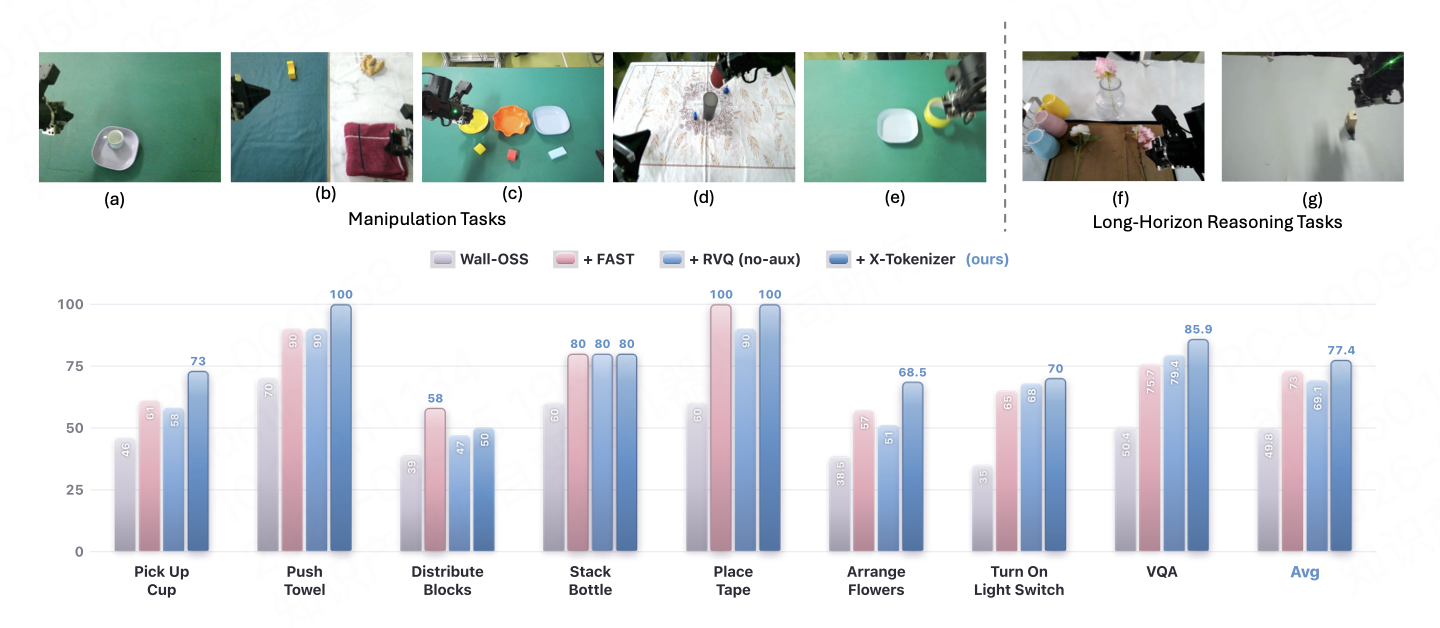
动作分词器 X-Tokenizer 的出色成绩表明,VLA 预训练的动作分词应该基于多模态上下文进行设计,而不是仅仅针对动作本身进行压缩优化。对于当前的 VLA 具身模型来说,动作分词不仅能进行信息的压缩,加快预训练阶段的收敛,同时对齐动作与其他模态信息也能带来巨大的性能提升,是未来具身领域动作分词器研究的重要方向。
项目主页:
https://x-square-robot.github.io/X-Tokenizer_projectPage
论文链接:
https://arxiv.org/pdf/2606.14752
GitHub:
https://github.com/X-Square-Robot/X-Tokenizer
https://huggingface.co/x-square-robot/X-Tokenizer
来源:自变量
2025年,人形机器人产业迎来爆发拐点。特斯拉Optimus量产在即,华为、宇树等企业加速技术突破,行业正从“实验室研发”向“规模化落地”跃迁为打通产业链上下游协作壁垒,艾邦机器人正式组建"人形机器人全产业链交流群",覆盖金属材料、复合材料、传感器、电机、减速器等全硬件环节,助力企业精准对接资源、共享前沿技术!
扫码关注公众号,底部菜单申请进群
