
Ego + UMI 正成为具身智能数据采集的重要路径。
Ego 第一视角让数据更接近机器人未来的观察方式;UMI 则支持低成本、灵活的人类操作采集,使动态、双手、精细和长程任务示范能够在真实环境中规模化获取,并为跨场景泛化提供更丰富的真实交互数据基础。
但对于具身模型而言,数据价值不仅取决于规模,更取决于空间精度。
当 Ego 与 UMI 时空对齐失准,或 UMI 空间定位存在误差时,模型学到的将不再是真实交互,而是带有偏差的动作监督信号,最终遭遇典型的 garbage in, garbage out。
目前,UMI 空间定位仍主要依赖 SLAM,但在弱纹理、动态干扰和遮挡环境下,其精度与稳定性往往受限。而这一问题,正在随着具身智能走向 in-the-wild 而被进一步放大。
真实世界的人类操作场景并非理想视觉环境。家庭、商业与开放场景中的光线环境、双手交互、复杂接触、快速操作以及长程任务,使得SLAM更容易出现轨迹误差与稳定性下降。
空间精度,仍是具身数据规模化的关键瓶颈。
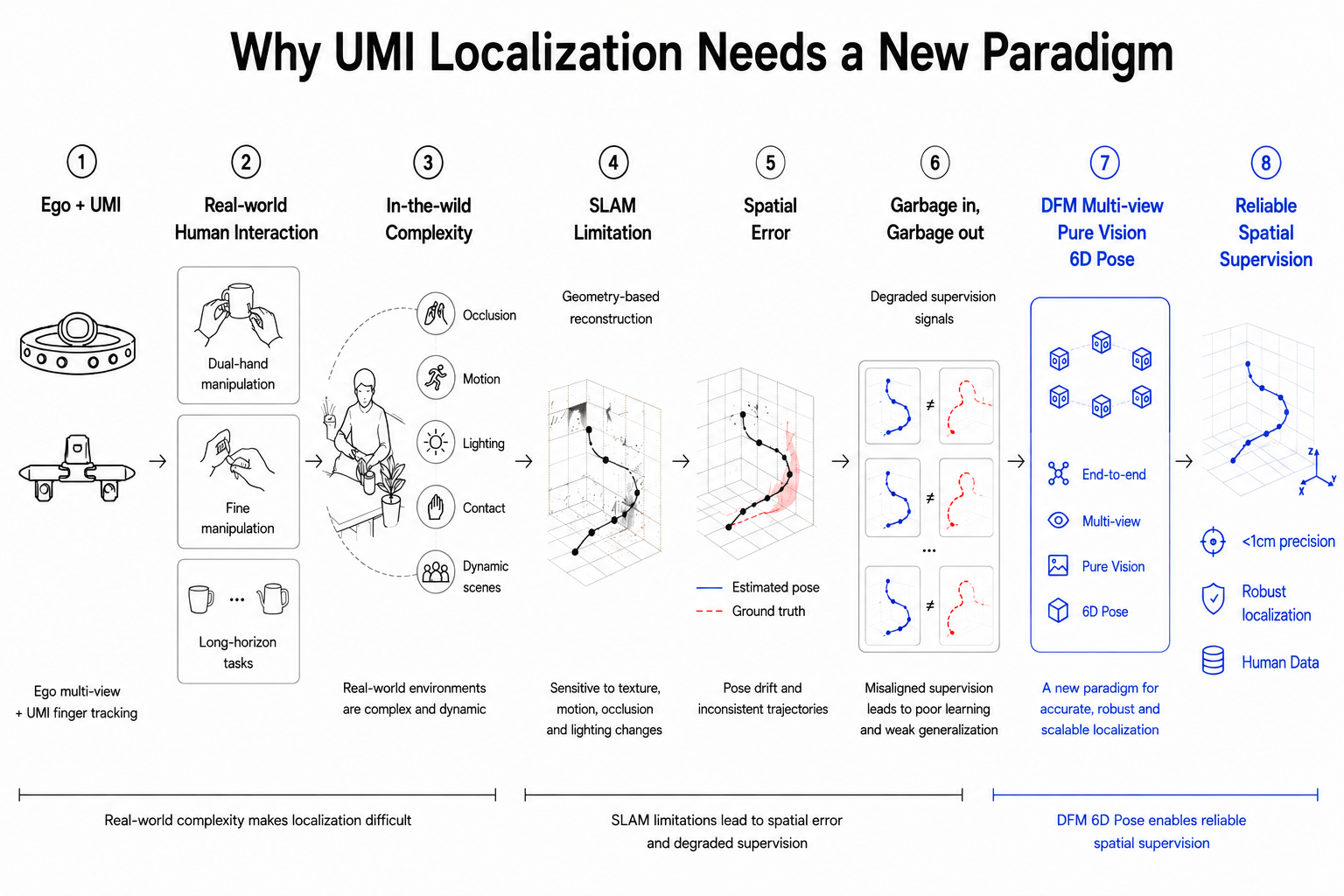
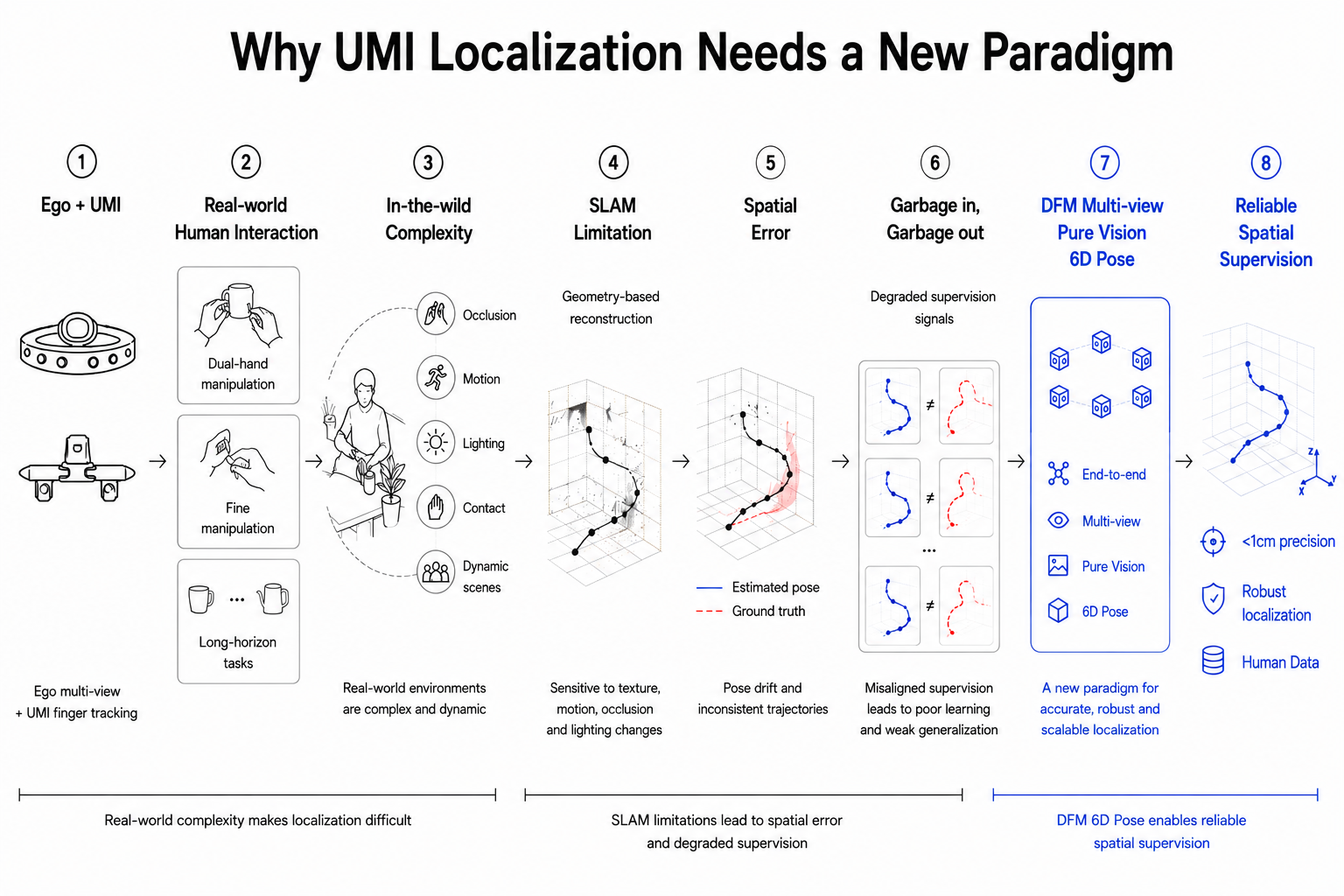
为解决这一问题,简智基于自研端到端具身数据模型 Data Foundation Model(DFM),提出一种面向 UMI 空间定位的新范式——多视角纯视觉 6D Pose (6D Pose,指目标在三维空间中的位置与姿态,即三维位置与三维旋转)。
不同于依赖 multi-stage 流程或深度输入的传统方案,DFM 利用 Ego 六路同步视觉,通过多视角 RGB 输入直接完成 UMI 6D Pose 计算,实现毫米级轨迹输出,并在纯色、无纹理等环境下展现出更好的泛化性。
这意味着,UMI 空间定位正从依赖传统 SLAM 的几何重建路径,走向端到端、多视角、纯视觉的新范式,为具身智能提供更高精度、更强鲁棒性的空间监督基础。
为什么是多视角纯视觉 6D Pose?
基于上述挑战,UMI 空间定位需要一种不同于传统几何重建的技术路线。
简智的思路,并不是继续增加定位链路中的中间环节,而是利用 Ego 数据天然具备的优势——多视角同步视觉。

图:简智 Ego+Fingers
相比 Finger 自身定位,Ego 多视角输入能够提供更稳定的空间约束,有效降低遮挡、弱纹理与视角歧义带来的定位不确定性。当具身数据走向 in-the-wild,空间定位面对的已不再是单一、受控环境,而是持续变化的真实场景。
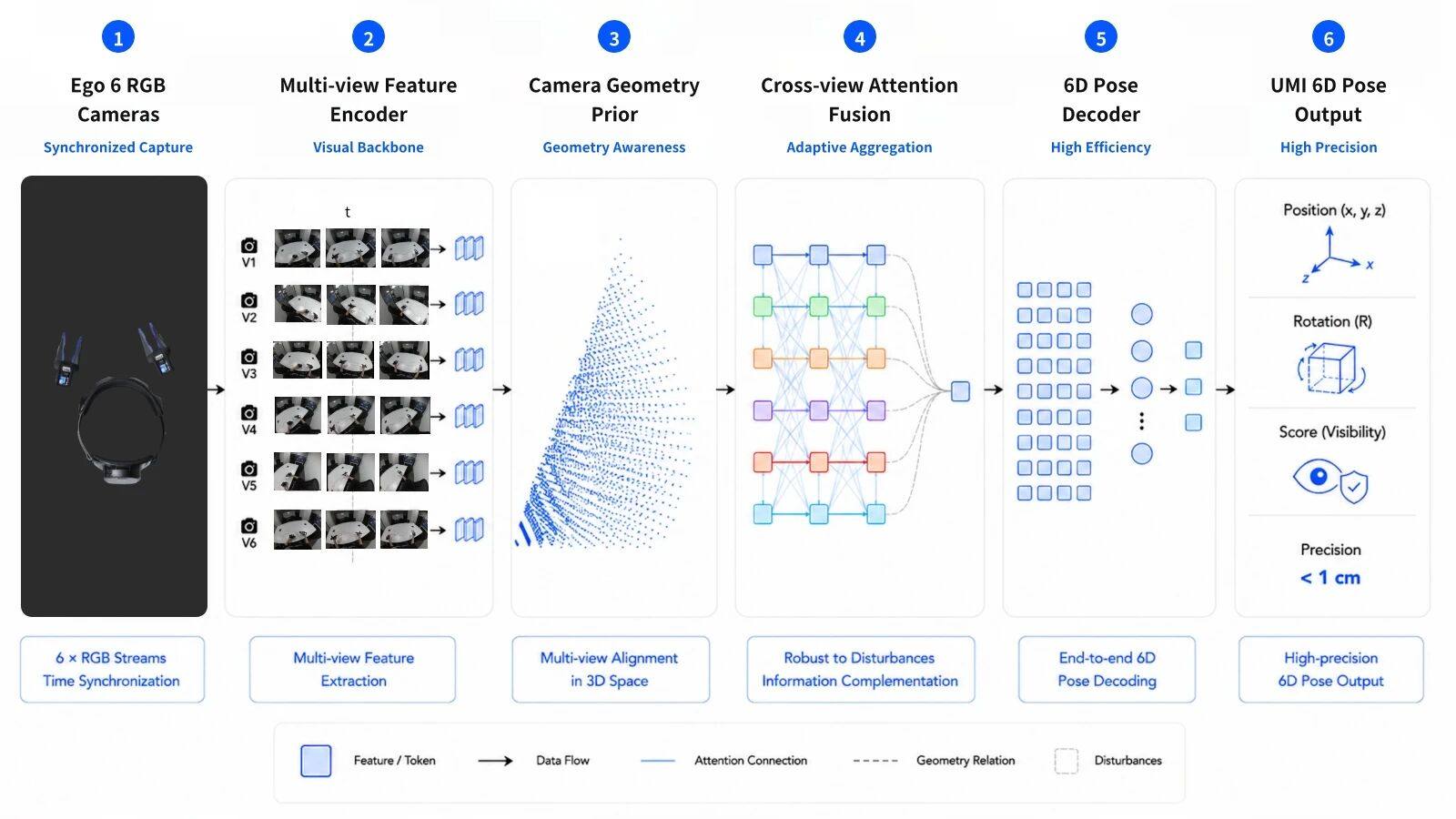
为此,简智基于 Data Foundation Model(DFM),构建了一套面向 UMI 空间定位的端到端多视角纯视觉 6D Pose 架构。
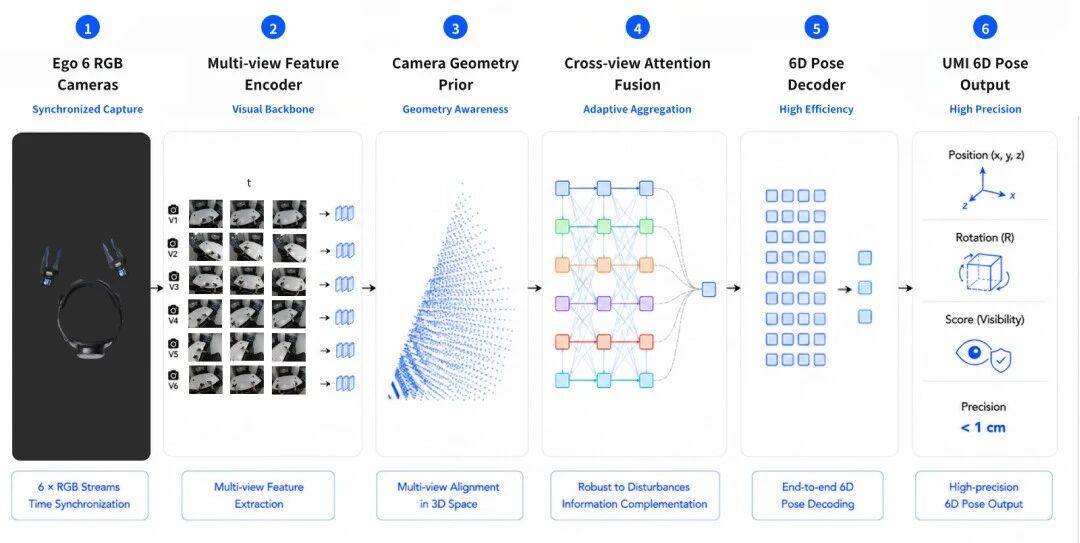

图:简智 6D Pose 技术方案
1、多视角时序统一架构
通过多路同步视觉输入进行联合学习,在更大范围内感知目标的空间关系。相比单视角方案,多视角联合建模能够获得更加完整的场景信息。当部分视角出现遮挡、快速运动或图像质量下降时,系统仍可利用其他视角的信息进行补充,从而提升整体鲁棒性。同时,时序信息的引入使模型能够利用连续帧之间的运动一致性,进一步增强轨迹连续性与预测稳定性,为后续空间理解和位姿估计提供可靠基础。
2、几何引导跨视角融合模块
多视角信息的价值不仅在于数量,更在于如何有效融合。
DFM采用几何引导跨视角融合机制,利用相机内外参建立显式几何约束,引导多视角信息高效交互。相比传统全局特征融合方式,该设计显著减少无效计算,以更低计算量高效实现更精准的信息聚合,在复杂遮挡和动态场景下获得更完整、稳定的场景表征。
3、稀疏 Query 驱动位姿聚合
稀疏Query驱动位姿聚合机制通过少量目标感知Query从多视角特征中提取与位姿预测相关的关键信息,避免对全量特征进行密集计算。该设计不仅显著降低计算复杂度,更能够引导模型聚焦稳定且具有判别性的空间特征,从而高效学习更加鲁棒的位姿表征,提升复杂场景下的泛化能力。
4、多任务共享协同增益
Hand Tracking、6D Pose、Depth 等任务之间存在天然关联,共同描述了目标、手部与环境之间的空间交互关系。如果分别训练多个独立模型,往往难以充分利用不同任务之间的互补信息。
采用多任务联合优化框架,在统一模型中同时学习多种监督信号。不同任务之间共享特征表示,并通过联合训练实现相互促进。例如,深度信息能够帮助位姿估计理解空间结构,而位姿信息又能够反向约束空间预测结果。通过多任务协同学习,模型能够获得更加丰富的空间认知能力,从而提升对未知场景和新任务的泛化能力。
此外,我们构建了完整的评测体系,对模型输出进行大规模量化评估,持续回答三个核心问题:模型精度究竟达到什么水平、在不同场景中的稳定性如何,以及当前能力边界位于何处。
因此,这一多视角纯视觉 6D Pose 方案并非单一算法模块,而是一套完整的 UMI 空间定位系统,覆盖原始数据采集、端到端 6D Pose 模型训练、Ground Truth 真值体系以及面向具身智能数据生产的规模化验证闭环,实现从数据到评测的全链路能力构建。
从更高精度空间定位,到更高质量 Human Data
基于多视角纯视觉 6D Pose 路线,我们不仅提升了 UMI 空间定位能力,也进一步提升了具身数据的质量与可用性:
-
更高空间精度:<1cm,提升模型训练效果
目前,简智的 6D Pose 空间精度已突破 1cm,使数据能够更准确地描述Fingers操作过程中的细微变化,为模型学习精细动作提供更可靠的监督基础。
-
更强的环境泛化能力:弱纹理、单色环境下,任务成功率提升 3.4 倍
相比依赖 Finger 自我单视角, Ego 多视角纯视觉路线展现出更强的环境适应能力。当部分视角受到强光照、高反射或局部信息缺失影响时,其余视角能够提供补充,提升 in-the-wild 场景下的泛化能力。在弱纹理、单色环境等典型挑战场景中,任务成功率提升 3.4 倍,综合成功率超过 95%。
-
更完整的灵巧操作捕捉:提升高价值数据产出
对于 UMI 数据采集而言,快速运动与遮挡始终是影响成功率的核心挑战。真实操作过程中,手部、工具与目标物体会频繁发生遮挡,物体也可能在短时间内快速移动或旋转,从而导致目标丢失、位姿漂移与轨迹不连续。多视角纯视觉路线确保了对人类灵巧操作过程更完整、更稳定地捕捉,以及更高比例的可训练数据产出。
-
更高效的多模态数据生产:效率提升 3.2 倍
相比依赖复杂 multi-stage 流程的传统方案,基于 DFM 端到端的 6D Pose 输出能力,减少了中间处理链路,使多模态数据生产能够并行处理,更加高效、稳定:1 分钟完成 Raw Data 到多模态数据转换,多模态数据生产效率提升 3.2 倍。
从单点算法,到持续演进的数据飞轮
高精度空间定位最终服务的,并不仅仅是轨迹输出,而是 Human Data 的生产。
简智正在构建的,并不是一个单点算法,而是一套面向具身智能的端到端多模态数据生成系统——Data Foundation Model(DFM)。
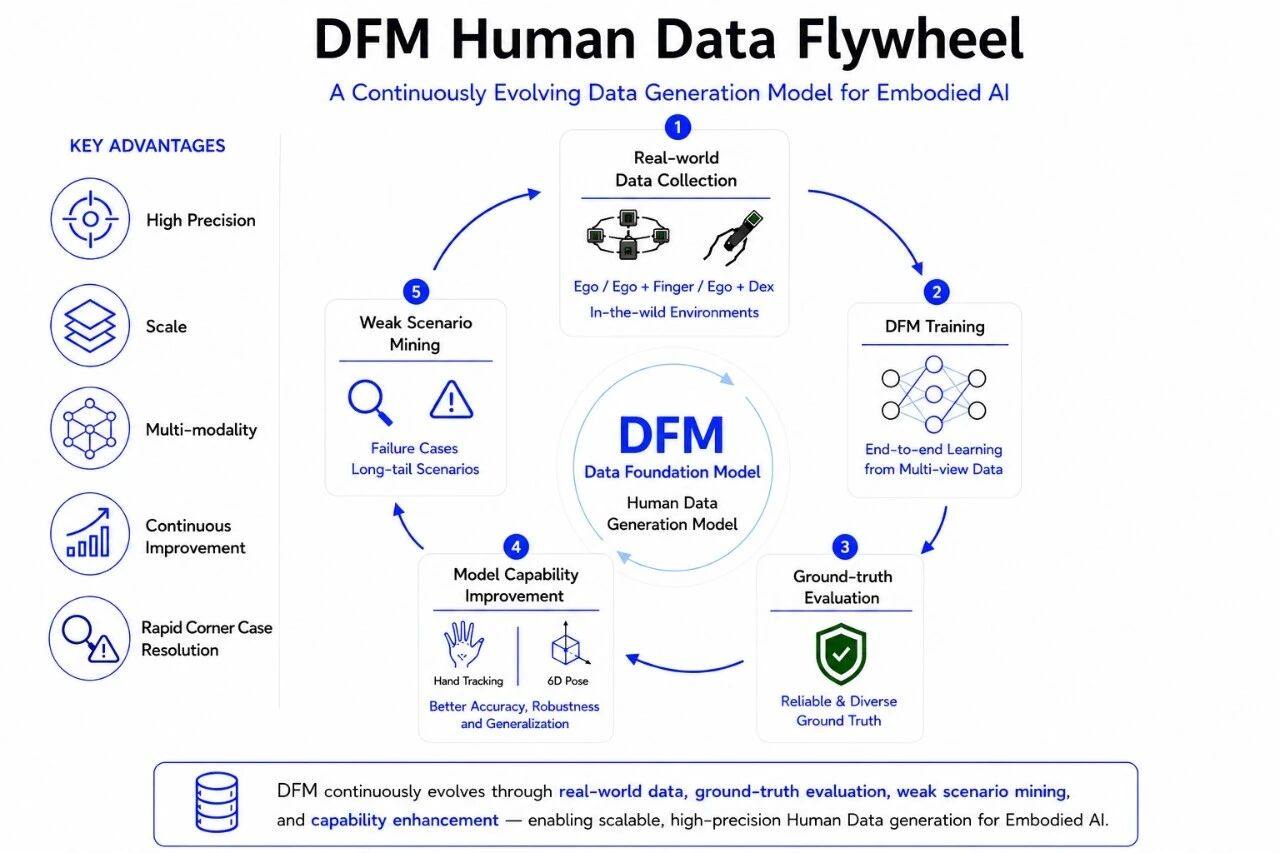
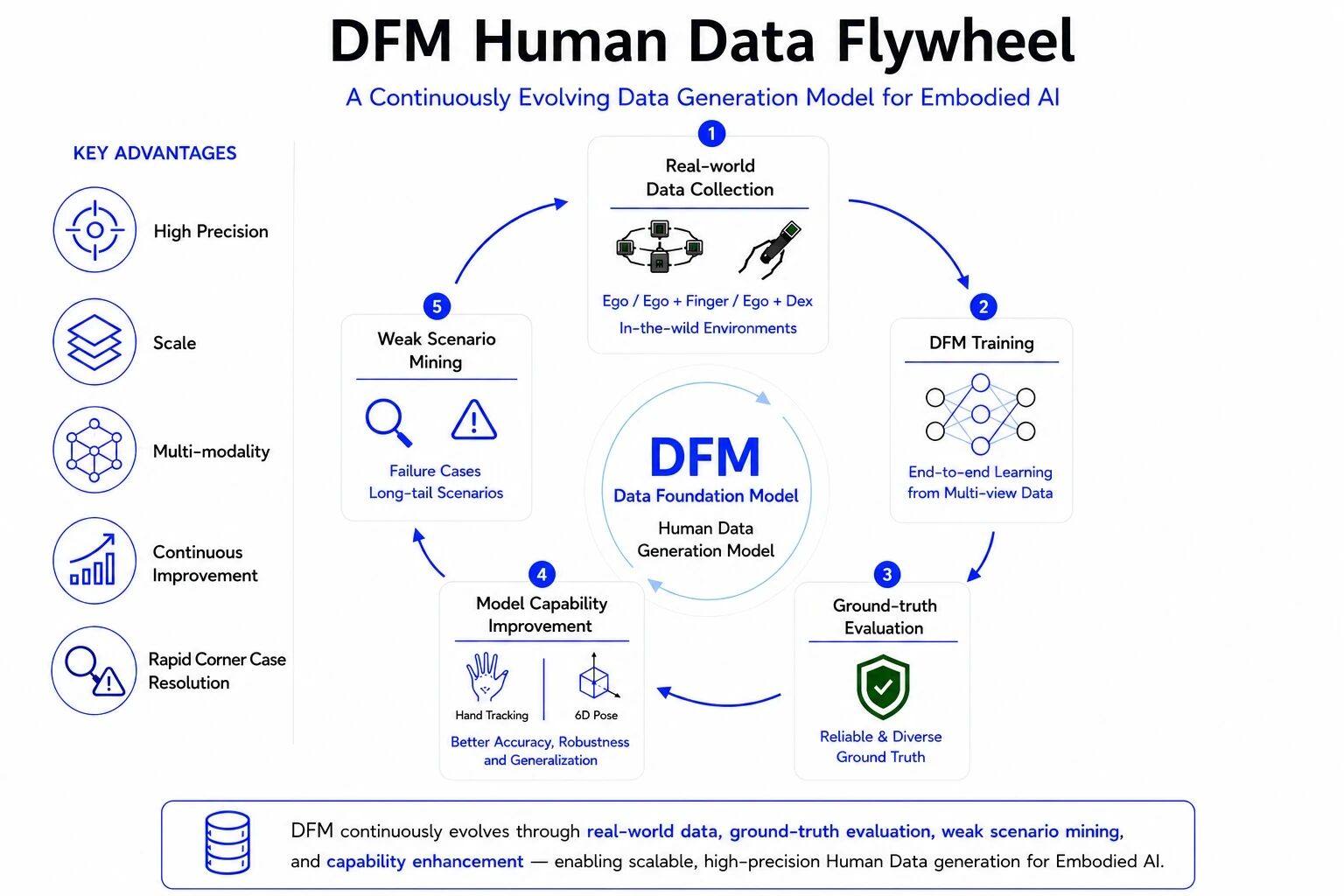
图:简智 DFM 数据飞轮
在 DFM 中,不同形态的 Ego 数据会生成不同类型的空间监督信号。
此前,我们介绍过 <1cm Hand Tracking 能力(点击阅读),其面向 Ego + 裸手数据,解决的是手部动作与轨迹追踪问题;而 DFM 的 6D Pose,则面向 Ego + Finger 数据,解决 Finger / UMI 设备在三维空间中的位置、姿态与轨迹定位。
这意味着,DFM 的核心价值并不在于某一个单点算法,而在于将不同形态的真实世界操作数据,高效、端到端地转化为多模态、高精度、大规模、可训练的Human Data。
更重要的是,DFM中的这些算法,正在真实数据、真值评测与模型训练之间形成持续演进的数据飞轮:真实数据持续增强空间监督;真值评测不断暴露模型边界;模型能力提升后,又进一步反向提升Hand tracking、6D Pose 等多模态数据生产能力。
对于具身智能而言,这不仅意味着更高精度、更多模态,也意味着 Human Data 具备持续进化与规模化生产的能力。
关注简智,下一期,我们将继续介绍 DFM 在 Human Data 生成中的其他关键能力。

2025年,人形机器人产业迎来爆发拐点。特斯拉Optimus量产在即,华为、宇树等企业加速技术突破,行业正从“实验室研发”向“规模化落地”跃迁为打通产业链上下游协作壁垒,艾邦机器人正式组建"人形机器人全产业链交流群",覆盖金属材料、复合材料、传感器、电机、减速器等全硬件环节,助力企业精准对接资源、共享前沿技术!
扫码关注公众号,底部菜单申请进群
